
Google erlaubt seit heute unter dem Arbeitsnamen Caffeine, einen Blick auf bereits fertiggestellte Teile des neuen Google-Fundaments. In den ersten Berichten und Blog-Postings zu dem Thema wird häufig von einer Reaktion auf den Yahoo/Microsoft-Deal gesprochen – ich glaube eher, dass Google in den letzten 3,5 Jahren (der Zeit, seit dem letzten großen Infrastruktur-Update) viel gelernt hat, es teilweise neue Anforderung gibt und man diese jetzt mit einem neuen System umsetzen will.
Da sich ja offenbar sonst niemand die Arbeit macht, habe ich mir die Beta etwas genauer angesehen und versucht, ein paar interessante Daten rauszuziehen. Die folgenden Diagramme und Tabellen basieren auf rund 10.000 englischsprachigen Keywords, die sowohl auf Google.com als auch in der Caffeine-Sandbox abgefragt und verglichen wurden. Die Beta scheint derzeit nur im englischen Sprachraum zuverlässig zu funktionieren, deutsche Keywords liefern häufig falsche oder sehr komische Ergebnisse.
Der erste Punkt ist die Geschwindigkeit, in der Google Ergebnisse ermittelt und zurückliefert. War Google auch bislang nicht dafür bekannt, dass das Durchsuchen des Indexes längere Zeit in Anspruch nimmt, konnte man hier offenbar trotzdem noch deutliche Verbesserungen erzielen:
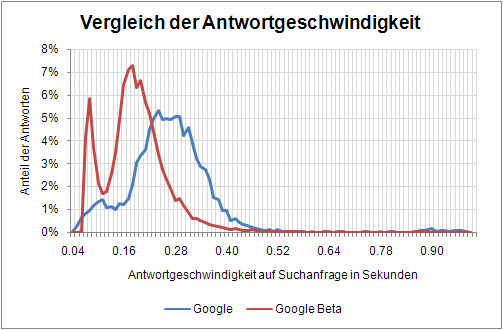
Abgetragen ist die Antwortgeschwindigkeit gegen den Anteil der Suchanfragen, die in dieser Zeit beantwortet wurden. Die Fläche unter den jeweiligen Kurven ist also der interessante Teil – und hier ist Caffeine nochmal bedeutend schneller als Google bislang sowieso schon. Interessant finde ich den Verlauf der beiden Graphen (Achtung: ab hier undifferenzierte und substanzlose Raterei): wenn man sowohl einen ersten, als auch einen zweiten („Supplemental“) Index hätte, könnte ich mir durchaus vorstellen, dass diese solch ein Bild ergeben.
Die zweite Auswertung betrifft die Anzahl der gefundenen Dokumente zu dem Suchbegriff. In folgendem Diagramm wurde ermittelt, welcher Index mehr Treffer anzeigt:
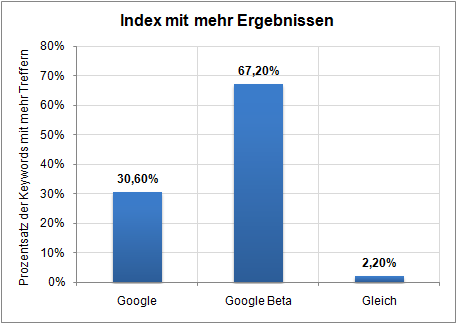
Deutlich zu sehen, dass die Google-Beta in rund zwei Drittel aller Fälle mehr Seiten findet als der bisherige Index. In nur 2,2 Prozent der Abfragen stimmt die Anzahl der Treffer überein. Gerade im Long-Tail dürfte dies Auswirkungen auf das Ranking haben, da der Algorithmus dort nun eine deutlich größere Auswahl hat und somit besser arbeiten kann.
Da die Ergebnisse aus dem Beta-Index nicht mit unseren bekannten Daten aus dem deutschsprachigen Google-Index vergleichbar sind, habe ich für sie eine Art „kleinen“ Sichtbarkeitsindex durchgerechnet. Hier sind einige bekannte Domains und die Entwicklung der Sichtbarkeit im Vergleich zum derzeitigen Google-Index:
| wikipedia.org | +8,02% |
| yahoo.com | -16,67% |
| amazon.com | +27,87% |
| tripadvisor.com | -3,49% |
| nextag.com | -3,66% |
| google.com | +0,25% |
| youtube.com | -1,09% |
| about.com | -3,38% |
| shopstyle.com | -6,56% |
| bizrate.com | -3,71% |
| yelp.com | +29,17% |
| ebay.com | -16,25% |
| zappos.com | +21,90% |
| blogspot.com | +28,28% |
| consumersearch.com | +0,23% |
| answers.com | +16,26% |
| facebook.com | +14,37% |
| linkedin.com | -36,17% |
| shopping.com | -3,84% |
| aol.com | -21,12% |
| epinions.com | -10,21% |
| merchantcircle.com | -27,14% |
| virtualtourist.com | +46,94% |
Entgegen der „gefühlten Mutmaßung“ geht es für Wikipedia.org nochmal ein Stück weiter nach oben, als großer Verlierer (wenn die Gewichtungen so bleiben wie derzeit im Beta-Index) dürfen sich wohl Yahoo und AOL, beides große Contentportale, fühlen.
