
Du kannst die Projekt-Einstellung „Virtuelle Robots.txt“ verwenden, um Verzeichnisse und URLs vom Crawl auszuschließen.
Sobald du ein Projekt geöffnet hast, findest du als letzten Punkt der oberen Navigation den Reiter „Einstellungen“. Unter „Onpage-Crawler: Experteneinstellungen“ findet sich dann der Punkt „Virtuelle Robots.txt“ .
Aktiviere die Einstellung, damit sich das Textfeld öffnet. Darin kannst du die Anweisungen hinterlegen, die an Stelle der Robots.txt auf dem Server berücksichtigt werden sollen.
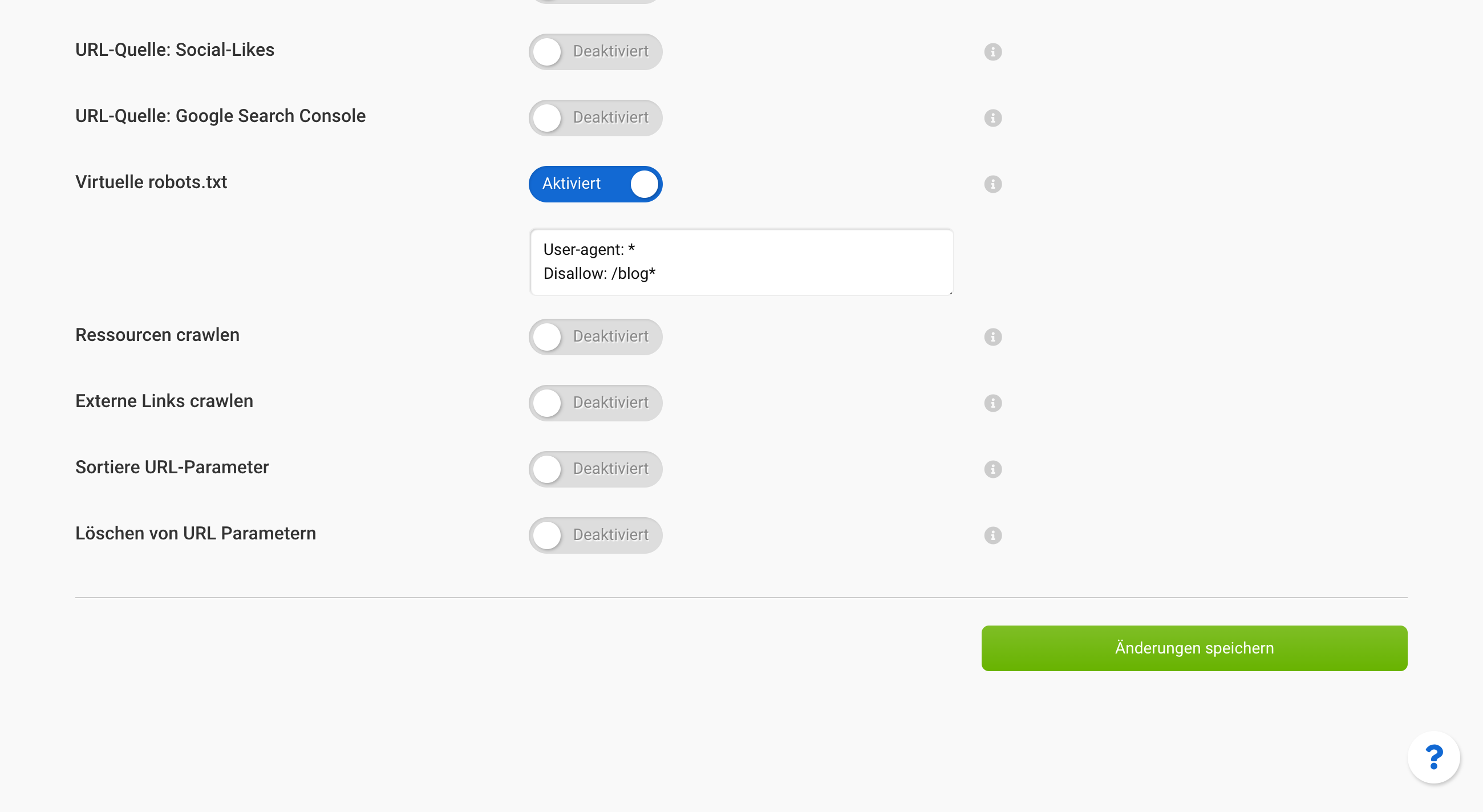
Das kann zum Beispiel so aussehen, um die ganze Seite ohne das Verzeichnisses /blog/ zu crawlen.
User-agent: *
Disallow: /blog/*
Die „Virtuelle Robots.txt“ hat den Vorteil, dass die Robots.txt auf dem Server unverändert bleibt. Eine Beschreibung dazu, wie Anweisungen in der Robots.txt zu formulieren sind findest du bei Google dokumentiert.