
Als Trailing Slash wird der letzte Schrägstrich (Slash) in einer URL bezeichnet. Je nach Position hat er Auswirkungen auf die URL oder wird von Browsern und Suchmaschinen verworfen.
Der Trailing Slash am Ende einer URL hatte ursprünglich den Zweck, ein Verzeichnis (https://sistrix.com/frag-sistrix/) von einer Datei ( https://sistrix.com/frag-sistrix.html) zu unterscheiden.
Da URLs heute weitgehend virtuell erstellt werden und keinen direkten Bezug zu den Dateien im Dateisystem des Webservers mehr haben, hat sich der Einsatzzweck von Trailing Slashes geändert.
Je nach Position des Trailing Slash in der URL, kann dieser Auswirkungen auf die URL haben und somit zu Duplicate-Content-Probleme bei Google führen.
John Mueller von Google hat sich der Thematik angenommen und erklärt, wann Trailing Slashes relevant sind und wann nicht:
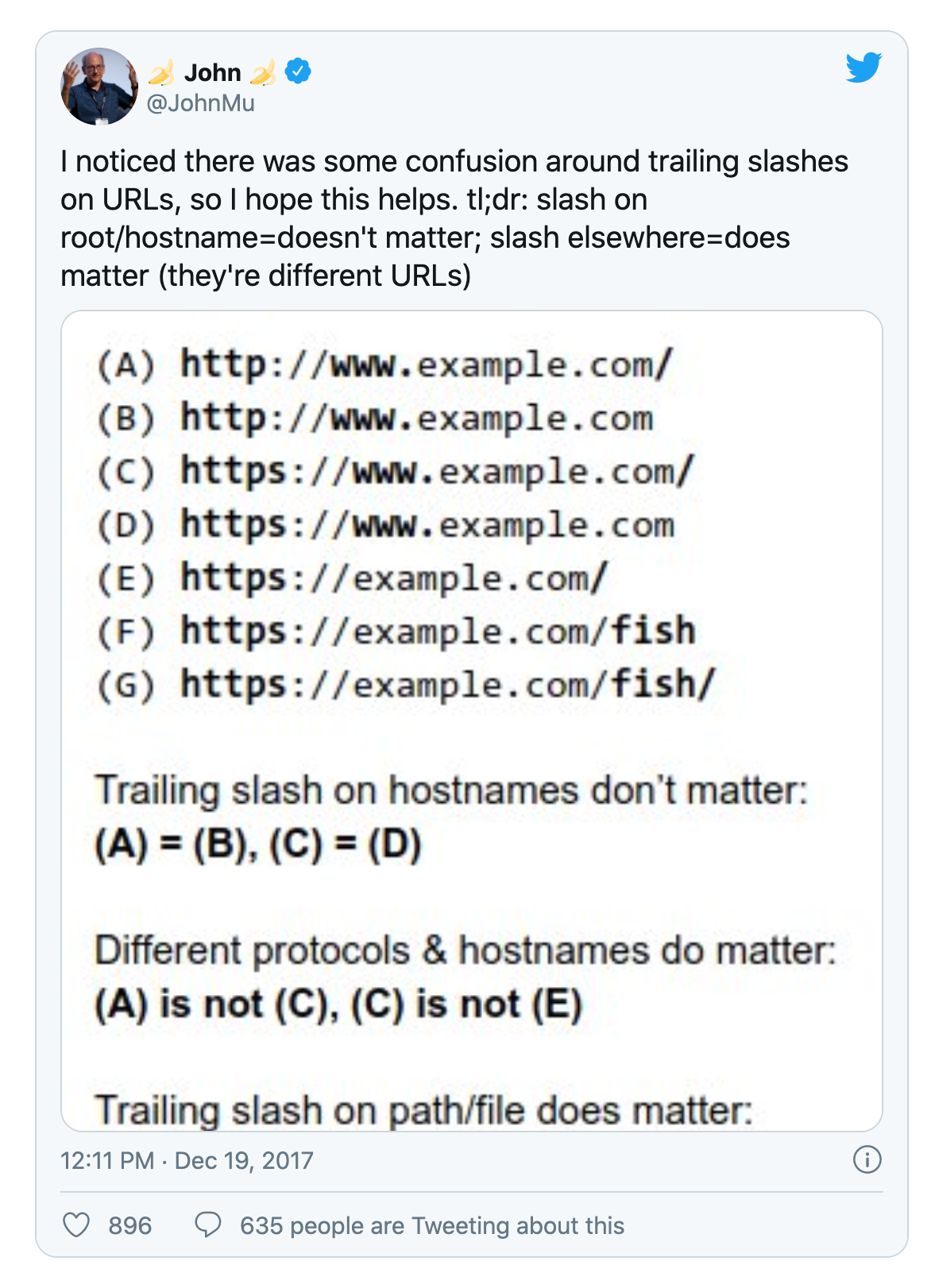
Am Ende eines Hostnamen macht es keinen Unterschied, ob ein Trailing Slash vorhanden ist oder nicht. Demnach würde ein Browser (und Google), zum Beispiel, https://sistrix.com genau gleich behandeln wie https://sistrix.com/.
Ganz anders sieht es aus, wenn der Schrägstrich Teil eines Pfades der Webseite ist. Nehmen wir „Frag Sistrix“. Hier macht es für Browser (und andere Nutzer wie auch den Googlebot) einen Unterschied, ob eine Seite auf https://sistrix.com/frag-sistrix oder https://sistrix.com/frag-sistrix/ liegt.
In diesem Fall handelt es sich um zwei unterschiedliche URLs, die jeweils eigene Ressourcen bereitstellen (können) und einem abfragenden System (zum Beispiel einem Browser) verschiedene Antworten geben können.
Für die Suchmaschinenoptimierung bedeutet dies, dass es schnell zu Problemen mit duplizierten Inhalten kommen kann, wenn das eigene System keine Unterscheidung zwischen URLs mit oder ohne Trailing Slash macht. Das System also auf beiden Versionen den gleichen Inhalt ausspielt und einen Status Code 200 (OK) versendet.
SISTRIX kostenlos testen
Beginne noch heute, mit SISTRIX deine Rankings zu verbessern.
- Kostenloser Testaccount für 14 Tage
- Unverbindlich, keine Kündigung notwendig
- Persönliches Onboarding durch Experten