
Abseits von „authentischen Links“ und „gutem Content“ gibt es eine ganze Reihe weiterer Faktoren, die Google in Zukunft für das Ranking von Websites verwenden könnte. Ich habe mir aktuelle Forschungsergebnisse der Computerlinguistik angeschaut und aus Sicht eines Suchmaschinenoptimierers interpretiert.

Auch wenn die Website der Conference on Intelligent Text Processing and Computational Linguistics (kurz CICLing) wie ein schlechter Scherz aussieht, ist sie inhaltlich hoch interessant und liefert Stoff für viele mögliche Rankingfaktoren, die Google heute oder in der Zukunft berücksichtigen könnte. Ich habe mir 19 Werke herausgepickt, die bei der CICLing 2013 akzeptiert wurden, und habe sie unter den Gesichtspunkten Brand, Content, SEO-Tools, Architektur und Authorship betrachtet.
Erklärung
Die folgenden Zitate sind immer nach diesem Schema aufgebaut:
Titel
relevantes Zitat
Autoren
Brand
Topic-oriented Words as Features for Named Entity Recognition:
Topic-oriented words are often related to named entities and can be used for Named Entity Recognition.
Zhang, Cohn und Ciravegna [Springer]
Zhang et al. versuchen hier nicht, die Brand-Keyword-Zuordnung als etwas Neues zu verkaufen. Sie setzen sie in ihrer Einleitung als etabliertes Wissen voraus, das keiner weiteren Erklärung bedarf. Was das mit SEO zu tun hat? Ein Beispiel: Auf der Website von Apollo-Optik kommt der Begriff „Brille“ nicht im Title und nur einmal im Content vor. Auch unter den sieben häufigsten Linktexten (geprüft mit MajesticSEO und SEOkicks) ist „Brille“ nicht zu finden.
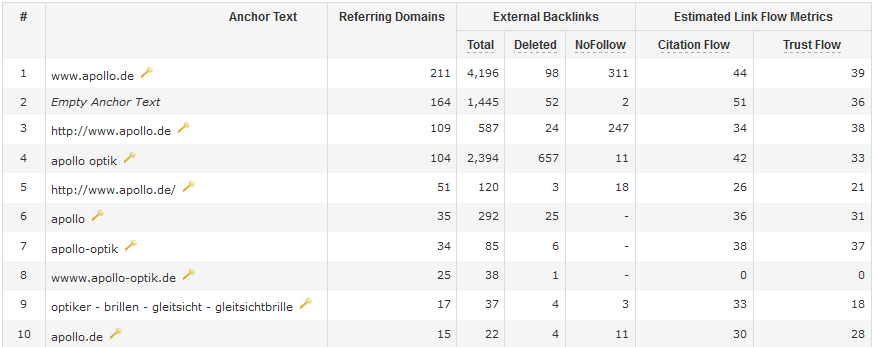
Warum also rankt Apollo.de bei Google auf der ersten Seite für „Brille“? Vermutlich weil Google Apollo-Optik als Brand erkannt hat, der in diversen Kontexten zusammen mit „Brille“ erwähnt wird. Ein Kontext kann zum Beispiel ein Text auf einer vertrauenswürdigen Internetseite sein. Aber auch Suchanfragen der Form „Apollo Optik Brille“ dürften berücksichtigt werden.

In den verwandten Suchanfragen von Google sieht man diesen Effekt sehr deutlich. Neben der Gleitsichtbrille, Filialen und Gutscheinen wird auch auf ähnliche Brands wie Fielmann und Abele Optik verwiesen.
Wenn Du also einen Brand aufbauen (oder faken :-D) möchtest, dann sorg dafür, dass Dein Brand in möglichst vielen Kontexten zusammen mit den Keywords genannt wird, die zusammen mit den wichtigsten Brands in Deinem Segment verwendet werden.
Extracting phrases describing problems with products and services from Twitter messages:
Automatic extraction of problem descriptions from Twitter data. The descriptions of problems are factual statements as opposed to subjective opinions about products/services.
Gupta [PDF]
Gupta zeigt Verfahren, mit denen aus Tweets über Produkte automatisch Problembeschreibungen zu diesen Produkten abgeleitet werden können. Wichtig ist, dass die Unterscheidung zwischen subjektiver Meinung und objektiver Problembeschreibung Teil dieses Verfahrens ist.
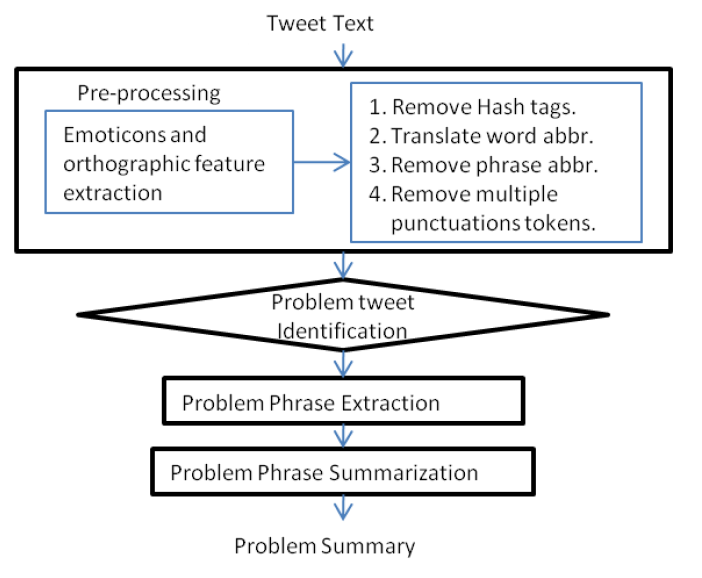
Google könnte erkennen, wenn schlecht über Deinen Brand berichtet wird. Ferner könnte Google für solche Analysen neben Tweets auch E-Mails, Chats, Kurznachrichten und Telefonate nutzen. Dank GMail, Google Talk, Google+, Hangouts, Chrome, Android, Chrome OS und Google Voice alles Dinge, auf die Google Zugriff hat!
Entity Linking by Leveraging Extensive Corpus and Semantic Knowledge:
Linking entities in free text to the referent knowledge base entries, namely, entity linking is attractive because it connects unstructured data with structured knowledge. […] Furthermore, we propose a novel model for the entity linking, which combines contextual relatedness and semantic knowledge. Experimental results on two benchmark data sets show that our proposed approach outperforms the state-of-the-art methods significantly.
Guo, Qin, Liu und Li
Noch ein Team von Wissenschaftlern, das sich mit Entitäten im Kontext von Texten beschäftigt. Und ähnliche Entitäten werden auch noch verknüpft. Ich möchte an dieser Stelle erneut auf mein obiges Beispiel hinweisen: Versuch die gleichen Signale wie die großen Brands in Deiner Nische zu bekommen!
Content
Cross-Lingual Projections vs. Corpora Extracted Subjectivity Lexicons for Less-Resourced Languages:
Subjectivity tagging is a prior step for sentiment annotation.
Saralegi, Vicente und Ugarteburu [Springer]
Saralegi et al. erfinden hier nicht die automatisierte Ermittlung von Subjektivität; sie setzen sie als bekannt voraus! Daraus folgt, dass Google wissen kann, ob ein Text eine objektive Produktbeschreibung oder ein subjektiver Erfahrungsbericht ist. Wenn Du Texte beauftragst, gib an, ob sie subjektiv oder objektiv geschrieben sein sollen.
Automatic distinction between natural and automatically generated texts using morphological and syntactic information:
Our work lies in the field of automatic metrics for assessing text quality. […] to distinguish normal texts written by man, on one hand, from automatically generated texts or automatically processed and intentionally damaged natural texts, on the other hand.
Tsinman, Dyachenko, Petrochenkov und Timoshenko
Tsinman at al. können vom Computer generierte Texte mit einer Genauigkeit von 96% erkennen. Also versuch gar nicht erst aus einer Tabelle von Produktdaten einen Text zu generieren.
Discursive Sentence Compression:
A method for Automatic Text Summarization by deleting intra-sentence discourse segments. First, each sentence is divided into elementary discourse units and then, less informative segments are deleted.
Molina, Torres-Moreno, Sanjuan, Cunha und Martínez [PDF]
Molina et al. sind in der Lage, Texte zu kürzen, in dem ein Algorithmus Textpassagen erkannt, die wenige Informationen enthalten und diese entfernt.

Was Du daraus lernen kannst?
- Ja, es ist möglich füllende Bullshit-Inhalte zu erkennen.
- Nein, es ist nicht gut „wegen Panda“ noch 400 Wörter Fülltext an jede Produktbeschreibung zu hängen.
Automatic Text Simplication in Spanish: A Comparative Evaluation of Complementing Components:
In this paper we present two components of an automatic text simplication system for Spanish, aimed at making news articles more accessible to readers with cognitive disabilities.
Drndarevic, Stajner, Bott, Bautista und Saggion
Wenn es Drndarevic et al. möglich ist, automatisiert simplere Versionen eines Textes zu generieren, dann kann Google auch die Komplexität Deiner Texte erkennen. Schreibe auf einem für Deine Zielgruppe angemessenem Niveau!
Text Simplification for People with Cognitive Disabilities: A Corpus-based Study:
This study addresses the problem of automatic text simplification in Spanish for people with cognitive disabilities.
Stajner, Drndarevic und Saggion
Stajner et al. liefern ein weiteres Beispiel für automatisierte Simplifizierung von Texten.
Automatic Detection of Outdated Information in Wikipedia Infoboxes:
Not all the values of infobox attributes are updated frequently and accurately. In this paper, we propose a method to automatically detect outdated attribute values in Wikipedia. The achieved accuracy is 77%.
Tran und Cao [PDF]
Ich hatte Language Arbitrage 2013 bei 50 Leute 100 Steaks als Grundlage für einen Wikipedia-Linkbuilding-Trick vorgestellt. Bereits 2009 hatten sich Adar et al. in ihrer Arbeit Information Arbitrage Across Multi-lingual Wikipedia mit dieser Thematik befasst.
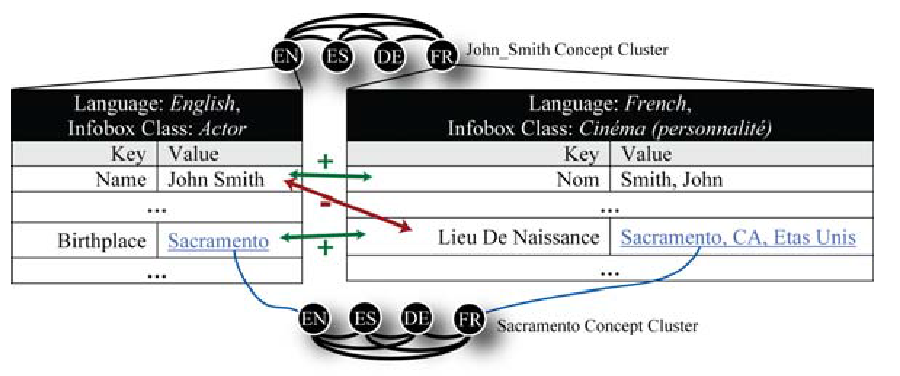
Jetzt haben Tran und Cao eine noch genialere Version gebaut, die über Google auf das komplette Internet zugreift. Und das alles ist so sauber dokumentiert, dass Du es nachbauen kannst!

Ich habe diese Arbeit unter „Content“ einsortiert, weil Dir klar sein sollte, dass Google auch Fakten aus Deinen (womöglich seit Jahren nicht geänderten) Texten verifizieren kann!
Automatic Glossary Extraction from Natural Language Requirements:
We present a method for the automatic extraction of a glossary from unconstrained natural language requirements. We introduce novel linguistic techniques in the identification of process nouns, abstract nouns and auxiliary verbs. The intricate linguistic classification and the tackling of ambiguity result in superior performance of our approach over the base algorithm.
Dwarakanath, Ramnani und Sengupta [IEEE]
Zum Mitschreiben: Du schmeißt ein langes Dokument in die Software von Dwarakanath et al. rein und bekommt einen Glossar der relevanten Begriffe raus. Wenn Du ein SEO bist, muss ich Dir nicht erklären, was man damit anstellen kann. Ganz blöd gedacht: Eine große Wikipedia-Kategorie nehmen, alle Artikel mit Länge < 500 Worte rausschmeißen und alle verbleibenden Artikel separat in den „Glossar-Macher“ schmeißen. Das Ergebnis mit entsprechendem MarkUp auf {Kategorie}-Lexikon.de stellen und schauen was passiert.
Facet-Driven Blog Feed Retrieval:
The faceted blog distillation task retrieves blogs that are not only relevant to a query but also satisfy an interested facet. The facets under consideration are opinionated vs. factual, personal vs. official and in-depth vs. shallow. Experimental results show that our techniques are not only effective in finding faceted blogs but also significantly outperform the best known results over both collections.
Jia und Yu [PDF]
Jia und Yu haben ein Information Retrievel System gebaut, mit dem sie nicht nur Blogartikel bestimmen können, die für eine Suchanfrage relevant sind. Sie gehen einen Schritt weiter und prüfen ob die Artikel das Interesse des Suchenden erfüllen. Dafür teilen sie Texte in die folgenden Kategorien ein:
- Meinung oder Fakten
- persönlich oder offiziell
- oberflächlich oder in die Tiefe gehend
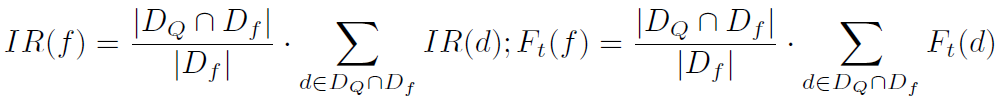
Je nach Suchkontext (z.B. abgeleitet aus Suchhistorie, Google+ Profil und aktuellem Standort) kann auch Google relevante Dokumente aus der einen oder anderen Kategorie bevorzugen. Es gilt also wieder: Kläre schon vor der Beauftragung von Texten, welche Ausprägung sie in jeder dieser Dimensionen haben sollen!
Predicting Subjectivity Orientation of Online Discussion Threads:
Topics discussed in online forum threads can be subjective seeking personal opinions or non-subjective seeking factual information. Hence, knowing subjectivity orientation of threads would help in satisfying users‘ information needs more effectively. Experimental results on two popular online forums demonstrate the effectiveness of our methods.
Biyani, Caragea und Mitra
Wenn Biyani et al. erkennen können, ob es in Diskussionen um Fakten oder persönliche Meinungen geht, dann kann Google das auch! Je nach Intention Deiner Seite, solltest Du also eventuell die Moderation der Kommentare und des Forums stärker fokussieren. Das Zauberwort lautet Community Management!
SEO-Tools
Analyzing the Sense Distribution of Concordances Obtained by Web As Corpus Approach:
Some authors have proposed using the Internet as a source of corpora […] based on information retrieval-oriented web searchers. This work analyzes the linguistic representativeness of concordances obtained by different relevance criteria based web search engines. Sense distributions in concordances obtained by web search engines are, in general, quite different from those obtained from the reference corpus.
Saralegi und Gamallo [Springer]
Saralegi und Gamallo zeigen, dass Text-Korpora, die auf Dokumenten basieren, die durch Google-Suchen gefunden wurden, in einigen linguistischen Eigenschaften nicht repräsentativ sind. Das bedeutet, dass es unter Umständen nicht ausreicht, die ersten 100 Suchergebnisse für das Keyword „Versicherung“ herzunehmen, um mit Maßen wie WDF-p-IDF oder n-Grammen zu rechnen.
N-Gram-based Recognition of Threatening Tweets:
We investigate to what degree it is possible to recognize tweets in which the author indicates planned violence.
Oostdijk und Halteren [Springer]
Dass Oostdijk und Halteren versuchen, Tweets zu erkennen, in denen die Absicht zur Gewalt ausgedrückt wird, hat nichts mit Online Marketing zu tun und ist hier nur als weiteres Beispiel für die Macht von n-Grammen aufgeführt. Übrigens: Was glaubst Du, wie die NSA vorgeht, wenn sie Deine Facebook-Chats analysiert? ;-)
Architektur
Single-Document Keyphrase Extraction in Multiple-Document Topical Keyphrase Extraction:
Here, we address the task of assigning relevant terms to thematically and semantically related sub-corpora and achieve superior results compared to the baseline performance. […] were considered better in more than 60% of the test cases.
Berend und Farkas
Du willst automatisiert Tags und Meta-Keywords für tausende von Dokumenten generieren? Dann solltest Du Dir dieses Verfahren von Berend und Farkas anschauen!
A knowledge-base oriented approach for automatic keyword extraction from single documents:
A generic approach for keyword extraction from documents. The features we used are generic and do not depend strongly on the document structure. We show that it improves the global process of keyword extraction.
Jean-Louis, Gagnon und Charton
Jean-Louis et al. liefern ein weiteres Verfahren, um automatisiert Tags und Meta-Keywords zu erzeugen.
Don’t Use a Lot When Little Will Do – Genre Identification Using URLs:
In this work we build a URL based genre identification module for Sandhan, search engine which oers search in tourism and health genres in more than 10 different Indian languages. While doing our experiments we work with different features like words, n-grams and all grams. Using n-gram features we achieve classification accuracies of 0.858 and 0.873 for tourism and health genres respectively.
Priyatam, Iyenger, Perumal und Varma [PDF]
Auch Priyatam et al. nutzen n-Gramme und sind in der Lage mehr als 80% aller URLs ohne Betrachtung des Inhalts thematisch zuordnen.
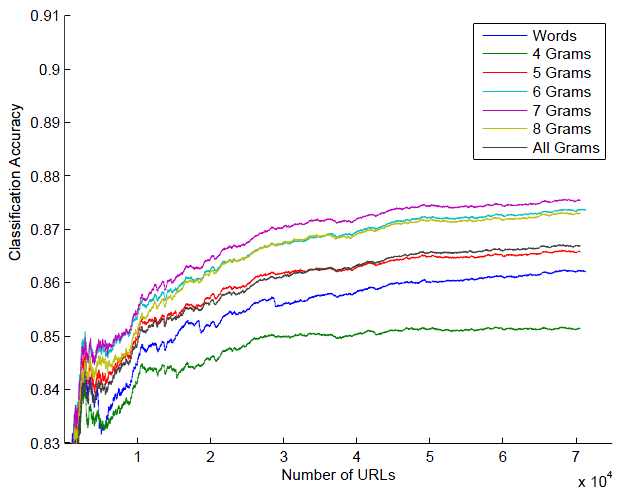
Vergiss niemals, dass Google bei aller Rechenpower jede unnötige Berechnung sparen wird, unter Umständen also auch auf diesen Trick zurückgreifen könnte. Pack die relevanten Keywords in die URL!
Authorship
The Use of Orthogonal Similarity Relations in the Prediction of Authorship:
Recent work on Authorship Attribution (AA) proposes the use of meta characteristics to train author models. The meta characteristics are orthogonal sets of similarity relations between the features from the different candidate authors. […] we achieve consistent improvement of prediction accuracy.
Sapkota, Solorio, Montes-Y-Gómez und Rosso [PDF]
Sapkota et al. erfinden hier nicht die automatische Zuordnung von Autoren zu Texten. Sie schlagen lediglich einen alternativen Algorithmus dafür vor. Wenn wir davon ausgehen, dass auch Google solche Verfahren einsetzt, könnte es eine ganz dumme Idee sein, von verschiedenen Menschen geschriebene Texte, mit dem Authorship-Markup des eigenen Google+ Profils zu versehen. Ebenso wenig solltest Du Texte eines einzigen Autors mit der Authorship verschiedener Fake-Accounts auszeichnen. Google wird in beiden Fällen merken, dass etwas faul ist und dem Autor und/oder der Domain das Autorenbild in den SERP entziehen.
Syntactic Dependency-based N-grams: More Evidence of Usefulness in Classification:
Sn-grams differ from traditional n-grams in the manner of what elements are considered neighbors. In case of sn-grams, the neighbors are taken by following syntactic relations in syntactic trees, and not by taking the words as they appear in the text. Sn-grams can be applied in any NLP task where traditional n-grams are used.
We describe how sn-grams were applied to authorship attribution. Obtained results are better when applying sn-grams.
Sidorov, Velázquez, Stamatatos, Gelbukh und Chanona-Hernández [PDF]
Alles Wichtige zur SEO-Sicht auf klassische n-Gramme kannst Du bei Jens Altmann nachlesen. Eine relevante Ergänzung ist, dass einige auf n-Grammen basierende Verfahren mit sn-Grammen noch besser funktionieren!
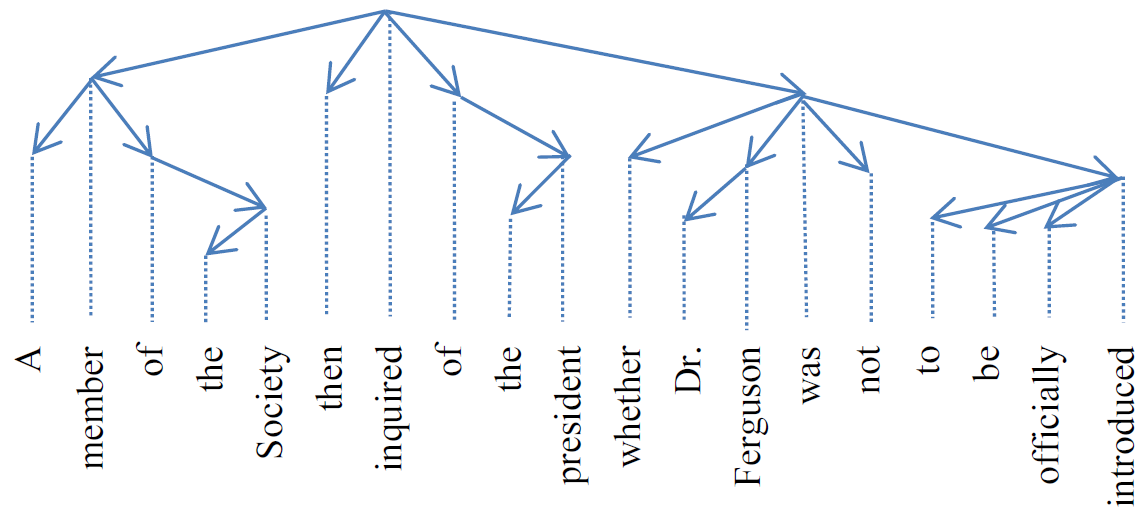
Außerdem ist die Arbeit von Sidorov et al. ein weiteres Beispiel dafür, dass es möglich ist, einem Text seinen Autor zuzuordnen. Siehe oben für die sich daraus ergebenden Konsequenzen.
Einschränkungen
Natürlich habe ich in der Interpretation der Forschungsergebnisse arg übertrieben. Häufig wurden die Verfahren nur auf eine einzige Sprache angewendet und mit wenigen Datensätzen verifiziert. Außerdem folgt daraus, dass sich irgendwo auf der Welt jemand mit einem Thema befasst nicht, dass auch Google dieses Thema auf dem Schirm hat. Dennoch darf nicht außer Acht gelassen werden, dass alle hier referenzierten Arbeiten es durch ein Peer-Review Verfahren geschafft haben, also von unabhängigen Wissenschaftlern, die auf dem gleichen Gebiet wie die Autoren forschen, abgenickt wurden. Und die CICLing ist nicht irgendeine Konferenz, sondern ist B-gerankt, gehört zu den Top 25% nach Download-Anzahl bei Springer, zählt laut Google Scholar zu den 6 wichtigsten Computer Linguistik Konferenzen und laut ArnetMiner zu den 8 wichtigsten NLP-Konferenzen nach Impact Factor. (Achtung: NLP steht in diesem Kontext für Natural Language Processing, also das automatisierte Verarbeiten der natürlichen Sprache!)
Eine kleine Anmerkung noch: [D]amit nicht jedes Zitat […] komplett verstümmelt aussieht, […] habe ich [relativ] frei zitiert ohne das jedes Mal expliziert zu kennzeichnen.
Schlusswort
Ich hoffe, es ist mir gelungen zu vermitteln, dass es in der Computerlinguistik eine ganze Reihe von Entwicklungen gibt, die in den nächsten Jahren für SEOs relevant werden könnten. Obwohl es in der deutschen SEO-Szene studierte Computerlinguisten gibt, setzt sich leider aktuell kaum jemand mit diesen Themen auseinander. Wenn ich den ein oder anderen motivieren konnte, das zu ändern, hat sich dieser Artikel gelohnt :-)