

Es wird immer deutlicher, dass der Ursprung eines Inhalts für Google und die Gewichtung der Suchergebnisse immer wichtiger wird. Die Einführung der “About this Result”- und “About the Author”-Informationen in den SERPs macht das sehr deutlich.
Speziell der Roll-out der “Perspectives” und der “About the Author”-Informationen rücken den Autor als Ursprung eines Inhalts in den Fokus.
Das E-E-A-T-Konzept spielt eine zentrale Rolle, um die Erfahrung, Expertise, Autorität und Vertrauen in den Autor zu bewerten.
E-E-A-T ist Googles Qualitätsoffensive
E-E-A-T ist Googles eigenes Konzept, um die Qualität der Suchergebnisse zu verbessern und damit die Nutzererfahrung mit den SERPs zu verbessern.
Dabei spielen sowohl Onpage-Faktoren wie die generelle Qualität der Inhalte (Coati), Linksignale wie PageRank und Ankertexte sowie Signale auf Entitäten-Ebene eine Rolle. (Mehr dazu in meinem Beitrag …)
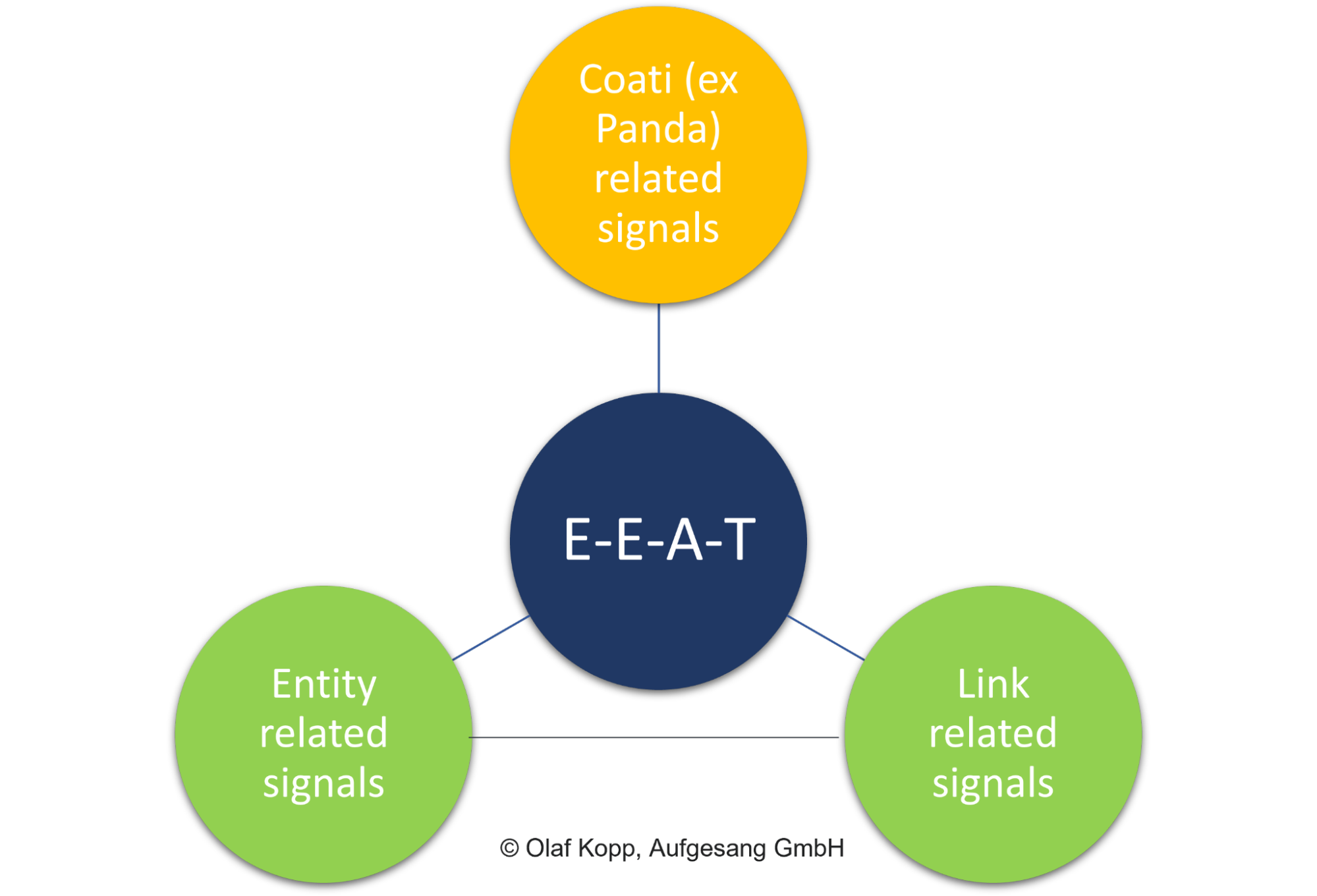
Im Gegensatz zum Dokumenten-Scoring steht die Bewertung einzelner Inhalte nicht im Fokus bei E-E-A-T. Das Konzept hat einen thematischen Bezug und einen Bezug zur Domain- und Urheber-Entität – unabhängig von der Suchintention und dem einzelnen Inhalt an sich. (Mehr dazu im Beitrag ….). E-E-A-T ist eine von den Suchanfragen unabhängige Einflussgröße.
E-E-A-T bezieht sich vor allem auf thematische Bereiche und ist wie ein Bewertungs-Layer zu verstehen, der weniger einzelne Dokumente bewertet, sondern Sammlungen von Inhalten und Offpage-Signale in Bezug auf Entitäten wie Unternehmen, Organisationen, Personen und deren Domains berücksichtigt.
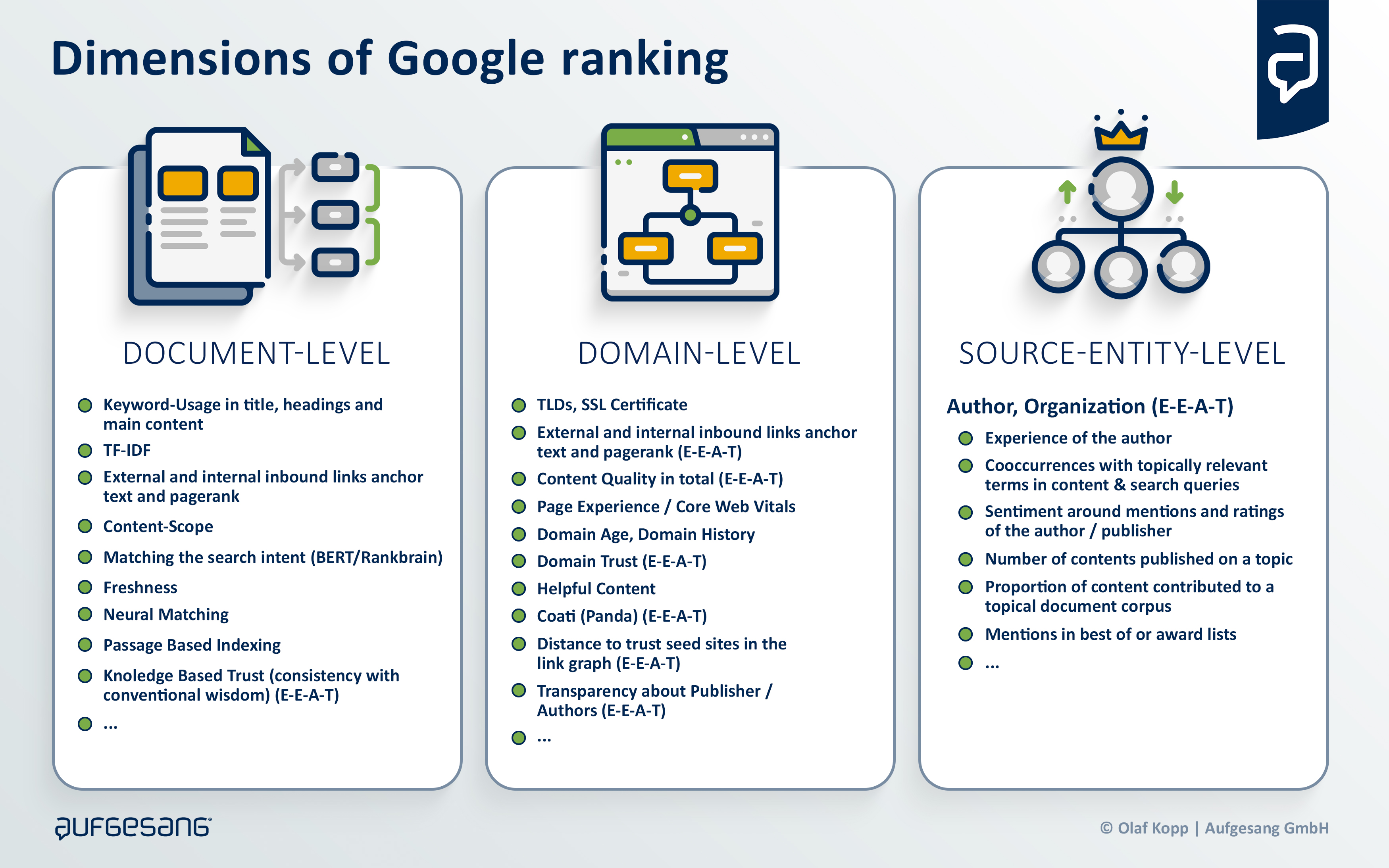
Die Bedeutung des Autors als Ursprung eines Inhalts
Schon lange vor (E-)E-A-T hat Google versucht, die Bewertung der Quelle eines Inhalts in das Ranking miteinzubeziehen. Zu nennen ist z.B. das Vince-Update aus dem Jahr 2009, bei dem die Inhalte von Brands im Ranking bevorteilt wurden.
Über bereits lange beendete Projekte wie Knol oder Google+ hat Google versucht, Signale für eine Autoren-Bewertung über z.B. einen Social Graph und Nutzer-Bewertungen zu sammeln.
So findet man in den letzten 20 Jahren einige Google Patente, die auf Content-Plattformen wie Knol oder soziale Netzwerke wie Google+ direkt oder indirekt verweisen. Auf einige werde ich im Verlauf des Artikels eingehen.
Den Ursprung bzw. den Autoren eines Inhalts nach den Kriterien von E-E-A-T zu bewerten, ist ein wichtiger Schritt und eine fundamentale Weiterentwicklung beim Ranking von Suchergebnissen.
Auch mit Blick auf die Fülle an KI-generiertem Content, aber auch klassischem Spam ist es ein wichtiger Schritt. Es macht für Google keinen Sinn, minderwertige Inhalte in den Suchindex zu übernehmen. Je mehr Inhalte Google indexiert und im Information-Retrieval-Prozess verarbeiten muss, desto mehr Rechenleistung wird benötigt.
E-E-A-T kann Google helfen, basierend auf Entitäten bzw. Domain- und Autoren-Ebene im Big Scale zu bewerten, ohne jeden einzelnen Inhalt crawlen zu müssen. Auf dieser Makro-Ebene lassen sich Inhalte gemäß der Urheber-Entität klassifizieren und mit mehr oder weniger Crawlingbudget ausstatten. Zudem kann Google über diesen Weg ganze Inhaltsgruppen von der Indexierung ausschließen.
Wie kann Google Autoren identifizieren und Inhalten zuordnen?
Autoren sind Entitäten des Typs “Person”. Unterschieden muss werden zwischen Entitäten, die bereits bekannt sind und im Knowledge Graph erfasst sind, und bisher unbekannten oder nicht validierten Entitäten, die in einem Knowledge Repository wie z.B. dem Knowledge Vault erfasst sind.
Auch wenn Entitäten noch nicht im Knowledge Graph erfasst sind, ist es für Google über Machine Learning und Sprachmodelle möglich, Personen-Entitäten aus unstrukturierten Inhalten zu erkennen und zu extrahieren. Die Lösung ist Named Entity Recognition (NER), eine Teilaufgabe im Natural Language Processing.
Bei der Named Entity Recognition werden aufgrund von linguistischen Mustern Entitäten erkannt und Entitätstypen zugeordnet. Pauschal kann man sagen, Substantive sind (benannte) Entitäten.
Moderne Information-Retrieval-Systeme nutzen dafür Word-Embeddings (Word2Vec). Jedes Wort eines Textes oder Textabschnitts wird in einem Vektor aus Nummern dargestellt und Entitäten können als Node Vektoren bzw. Entitäten Embeddings (Node2Vec/Entity2Vec) dargestellt werden.
Über Part of Speech Tagging (POS) werden Wörter einer grammatikalischen Klasse (Nomen, Verb, Präpositionen …) zugeordnet.
Nomen sind i.d.R. Entitäten. Subjekte die Haupt-Entitäten, Objekte die Neben-Entitäten. Verben und Präpositionen können die Beziehung der Entitäten untereinander beschreiben.
Ein Beispiel macht das Ganze verständlich: “olaf kopp”, “head of seo”, “co founder” und “aufgesang” sind im Folgenden die benannten Entitäten. (NN = Nomen).
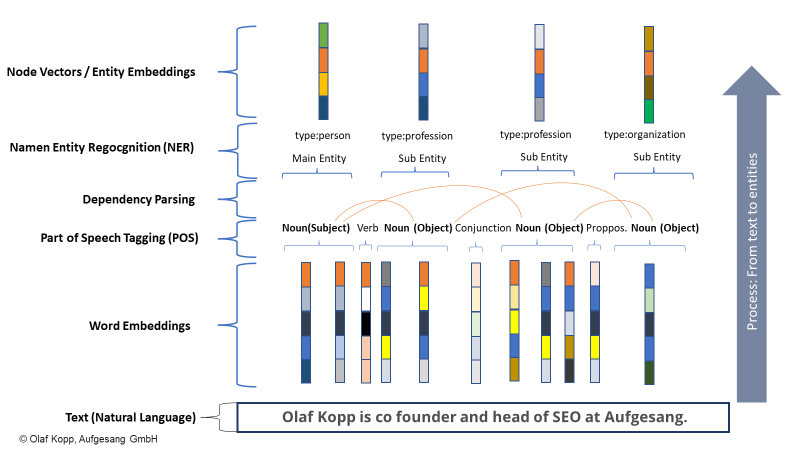
Über Natural Language Processing lassen sich nicht nur Entitäten identifizieren, sondern auch die Beziehung zwischen ihnen ermitteln. Dadurch entsteht dann ein semantischer Raum, der das Konzept einer Entität besser erfasst und verständlich macht.
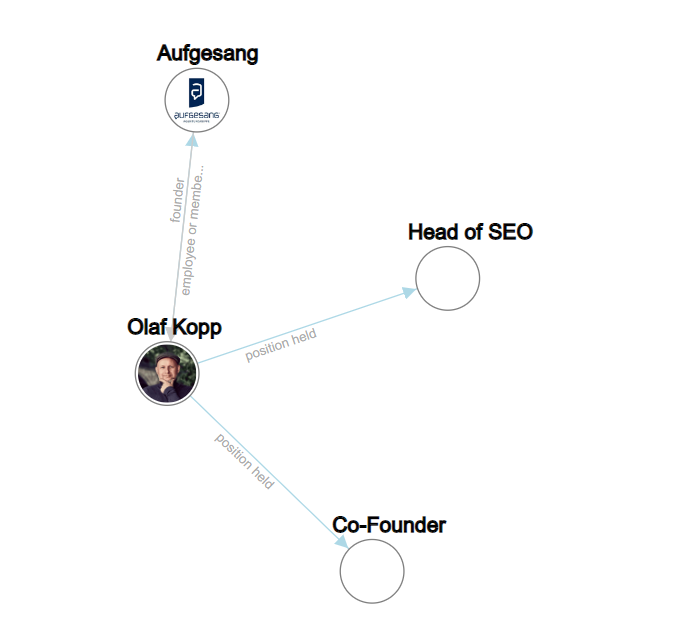
Mehr dazu findest du u.a. in meinen Beiträgen How Google uses NLP to better understand search queries, content, How Google can identify and interpret entities from unstructured content und Alles was Du als SEO zu Entitätstypen, -Klassen & Attributen wissen solltest.
Das Gegenstück zu den Autoren-Embeddings sind die Dokumenten-Embeddings. Dokumenten-Embeddings werden über Vektorraumanalysen mit den Autoren-Vektoren abgeglichen. Mehr dazu im Google Patent Generating vector representations of documents.
Nicht nur Dokumente können als Vektoren dargestellt werden, sondern alle Arten von Content. Dadurch lassen sich Content-Vektoren und Autoren-Vektoren in Vektorräumen gegenüberstellen, Dokumente nach Ähnlichkeit clustern und Autoren zuordnen.
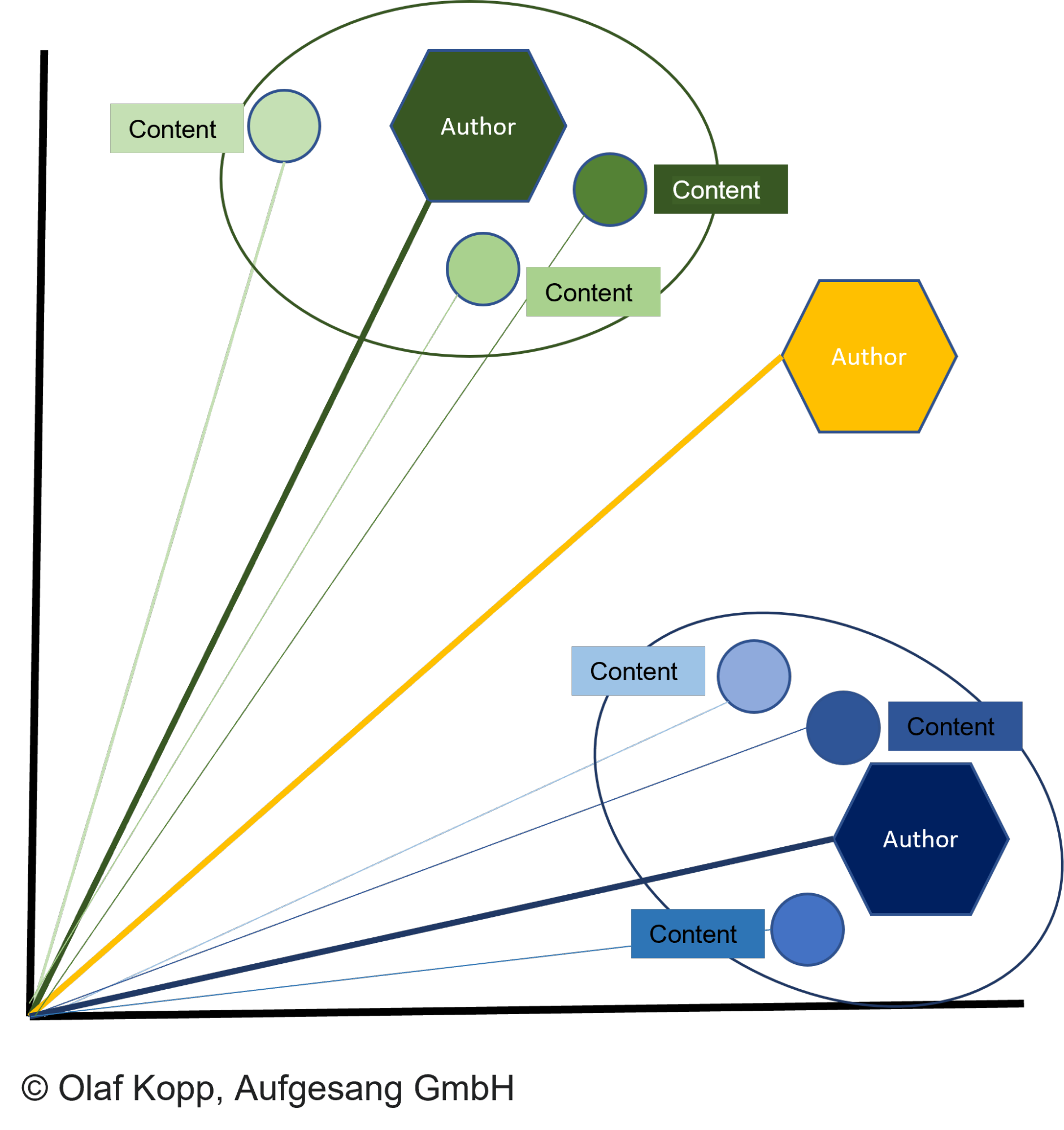
Der Abstand der Dokumenten-Vektoren zum entsprechenden Autoren-Vektor beschreibt die Wahrscheinlichkeit, dass die Dokumente von dem Autor erstellt wurden. Ist der Abstand kleiner als bei anderen Vektoren und ist ein bestimmter Schwellenwert erreicht, wird das Dokument dem Autor zugeordnet.
So kann auch verhindert werden, dass ein Dokument unter falscher Flagge erstellt wird. Die Zuordnung des Autoren-Vektors zu einer Autoren-Entität kann dann, wie bereits beschrieben, über den im Inhalt angegebenen Autorennamen erfolgen.
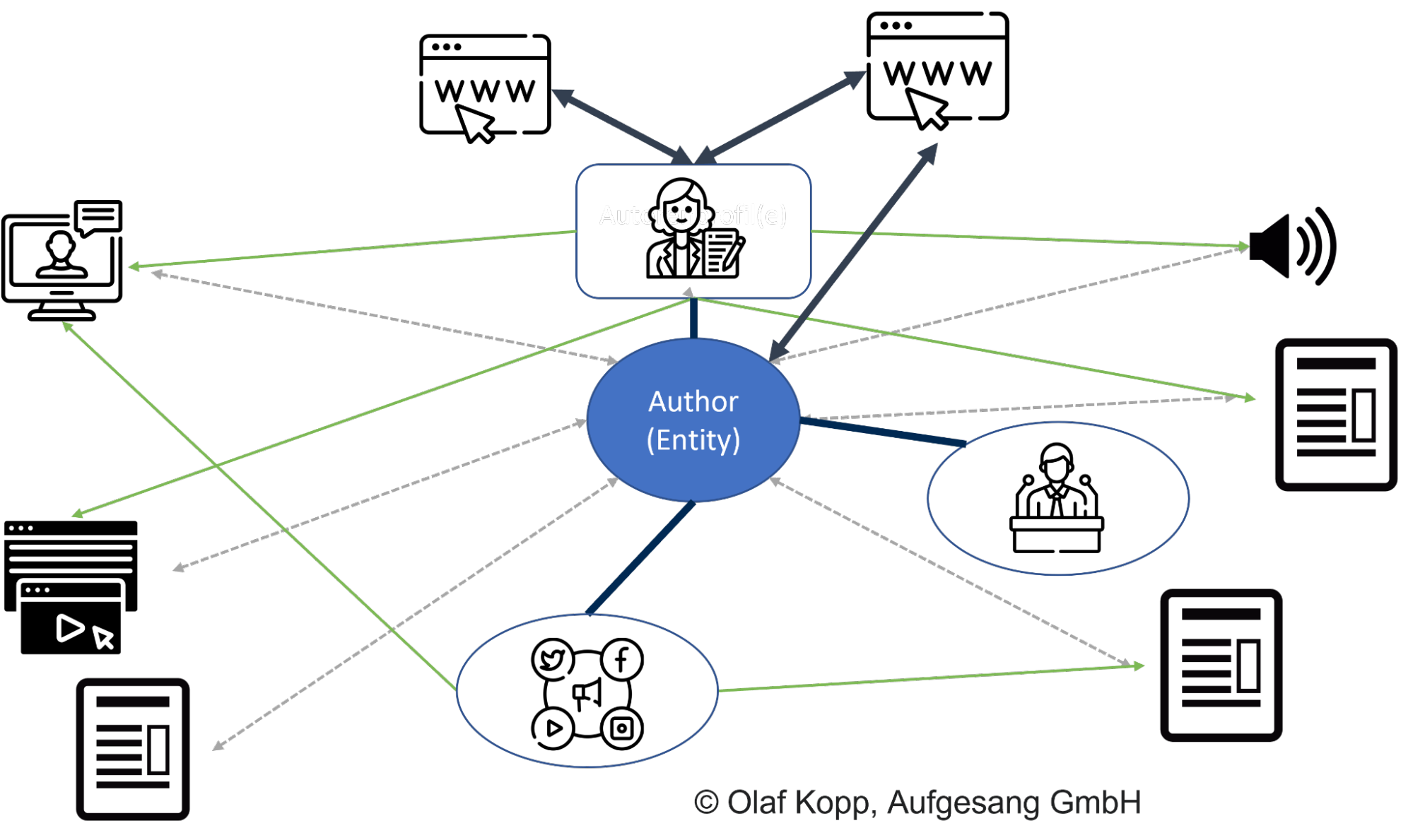
Wichtige Quellen zu Informationen rund um Autoren sind insofern vorhanden: Wikipedia-Einträge, Autorenprofile, Speaker-Profile oder Social Media-Profile.
Googelt man die Namen von Personen-Entitäten, findet man unter den ersten 20 Suchergebnissen vor allem Wikipedia-Einträge, Profile des Autors und URLs von Domains, die mit dem Autor in direkter Verbindung stehen.
In den mobilen SERPs kann man gut sehen, welche Quellen Google in eine direkte Beziehung zu der Personen-Entität herstellt. Alle Ergebnisse über den Icons zu den Social Media-Profilen hat Google als Quellen mit einem direkten Bezug zur Entität erkannt.
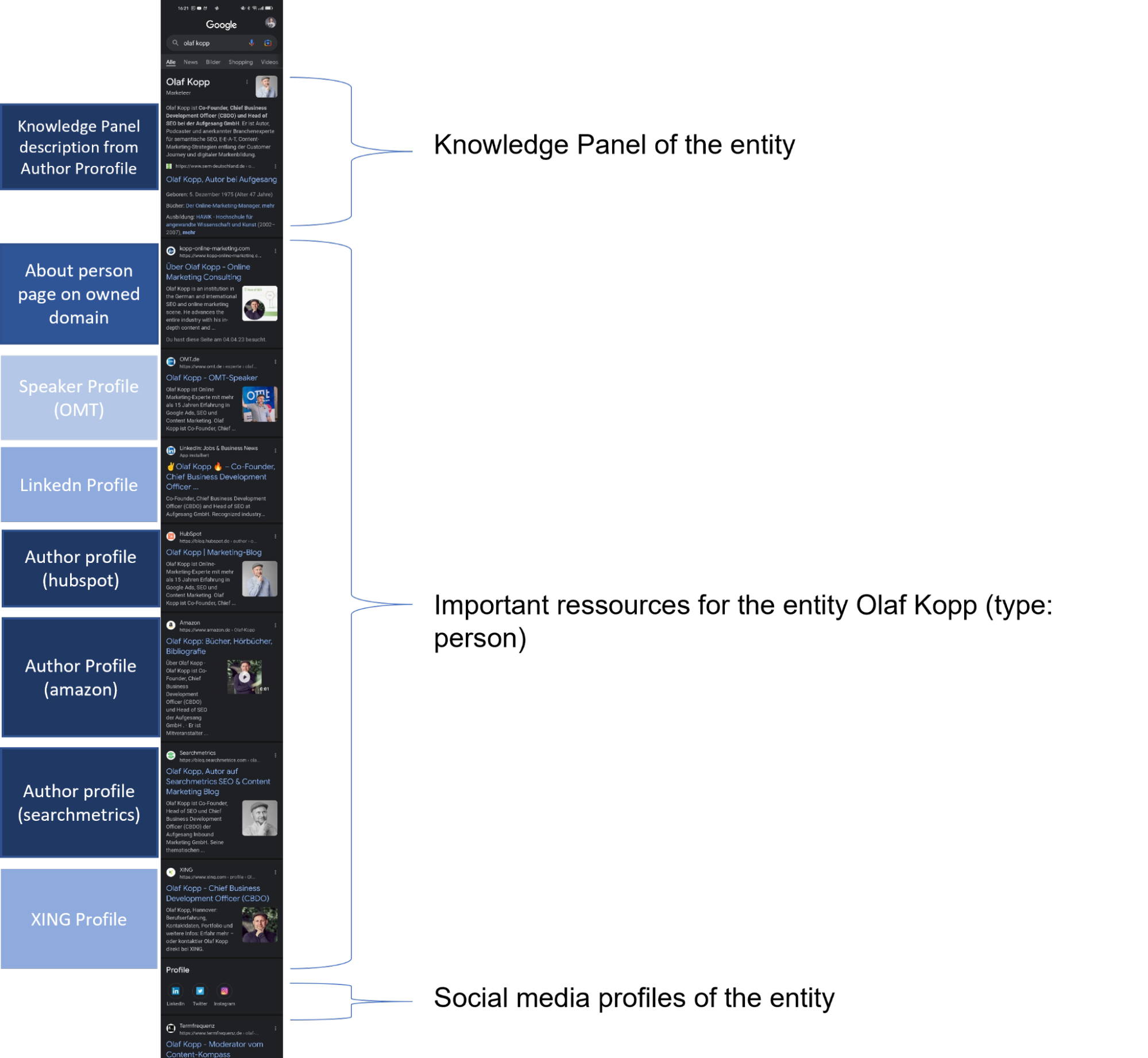
Dass Entiäten mit Quellen verknüpft werden, verdeutlicht dieser Screenshot bei der Suchanfrage zu “olaf kopp”. Auf dem Screenshot sieht man eine neue Variante eines Knowledge Panels. Es scheint als bin ich hier Teil eines Beta-Tests geworden.
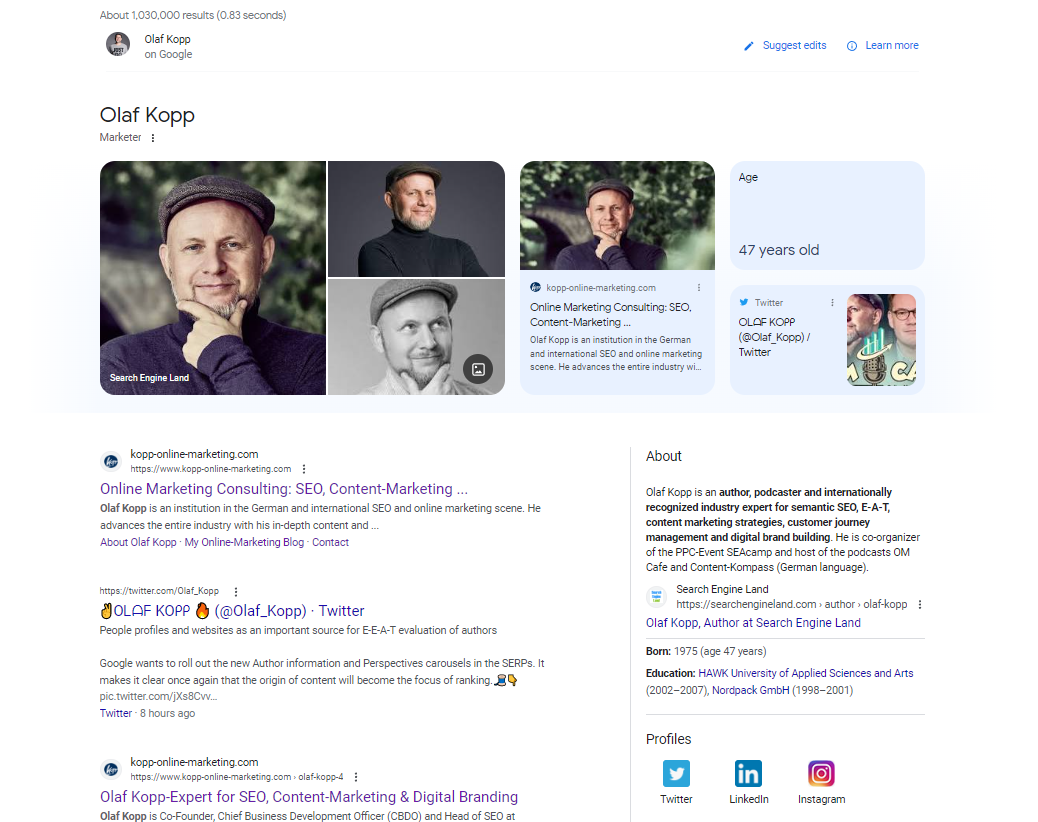
In diesem Screenshot kann man mehrere Dinge erkennen. Neben Bildern und Attributen (Alter) hat Google meine Domain und Social Media-Profile mit meiner Entität direkt verknüpft und liefert diese im Knowledge Panel aus. Da es keinen Wikipedia-Artikel zu meiner Person gibt, wird für die “About”-Beschreibung in den USA das Autorenprofil bei Search Engine Land und in Deutschland das Autorenprofil der Agentur-Website genutzt.
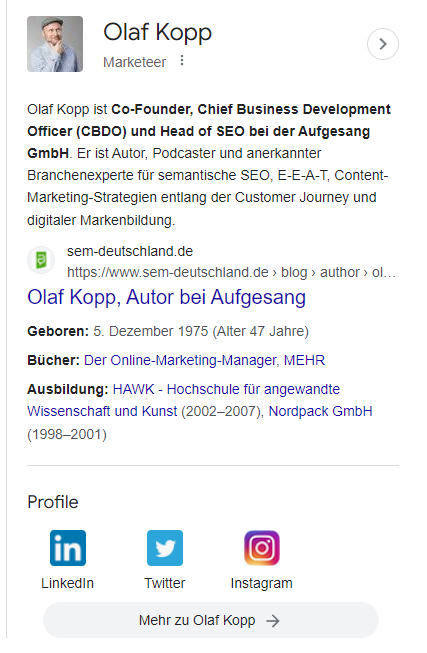
Personen-Profile im Internet helfen Google dabei, Autoren kontextuell einzuordnen und Social Media-Profile und Domains zu identifizieren, die mit einem Autor in Verbindung stehen. Autorenboxen oder -sammlungen in Autorenprofilen helfen Google dann wiederum dabei, die Inhalte den Autoren zuzuordnen. Der Autorenname reicht als Identifier nicht aus, da es zu Mehrdeutigkeiten kommen kann.
Deswegen sollte man darauf achten, alle Autorenbeschreibungen konsistent zu gestalten. Google kann sie nutzen, um die Validität der Entität im Abgleich zueinander zu prüfen.
Interessante Google Patente für die E-E-A-T Bewertung von Autoren
Die folgenden Patente sind interessant, um mehr über mögliche Methodiken herauszufinden, wie Google Autoren identifiziert, dem Content zuordnet und hinsichtlich E-E-A-T bewertet.
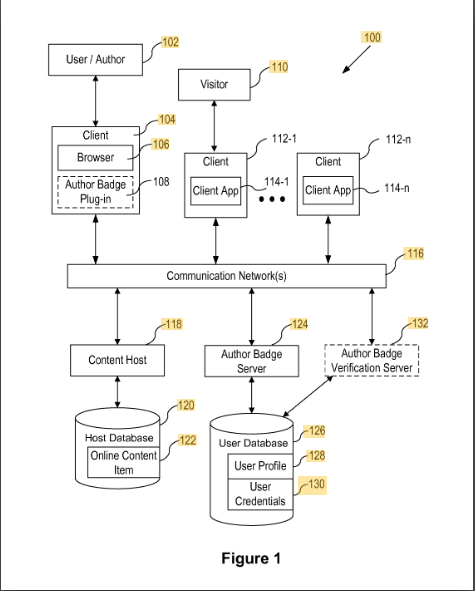
Content Author Badges
In diesem Patent wird beschrieben, wie Inhalte über ein Badge Autoren zugeordnet werden. Die Zuordnung des Contents zu einem Autoren-Badge erfolgt mit einer ID wie der E-Mail-Adresse oder dem Namen des Autors. Die Verifizierung erfolgt über ein Addon im Browser des Autors.
Generating author vectors
Dieses Google Patent ist erstmals 2016 von Google angemeldet worden und hat eine Laufzeit bis mindestens 2036. Allerdings gibt es bisher nur Patent-Anmeldungen für die USA, was darauf schließen lässt, dass es noch nicht weltweit in der Google-Suche zum Einsatz kommt.
In dem Patent wird beschrieben, wie anhand von Trainingsdaten Autoren als Vektoren dargestellt werden. Ein Vektor wird aufgrund typischer Schreibstile und der Wortwahl des Autors identifiziert. Über diesen Weg können sowohl Inhalte einem Autor ganz neu zugeordnet werden, als auch ähnliche Autoren in Clustern zusammengefasst werden.
Ein Ranking von Inhalten kann dann basierend auf dem Nutzerverhalten in der Suche oder z.B. bei Discover für einen oder mehrere Autoren angepasst werden. So würden Inhalte der bereits konsumierten Autoren und ähnlicher Autoren besser ranken.
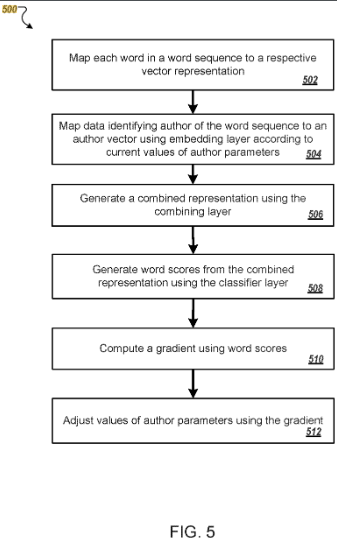
Dieses Patent beruht auf sogenannten Embeddings, in diesem Fall Autoren- und Word-Embeddings. Embeddings sind heutzutage technologischer Standard in Deep Learning und Natural Language Processing. Daher ist es naheliegend, dass Google solche Methoden auch für die Autorenerkennung und -zuordnung einsetzen wird.
Reputation scoring of an author
Dieses Patent wurde 2008 erstmals von Google angemeldet und hat eine Mindestlaufzeit bis 2029. Dieses Patent bezieht sich ursprünglich auf das schon lange geschlossene Google-Projekt “Knol”. Daher ist es umso spannender, warum Google es 2017 unter dem neuen Titel “Monetization of online content” nochmal gezeichnet hat. Knol wurde bereits 2012 von Google geschlossen.
In dem Patent geht es um die Ermittlung eines Reputation Scores. Dafür können folgende Faktoren berücksichtigt werden:
- “Level of frame” des Autors
- Veröffentlichungen in renommierten Medien
- Anzahl der Veröffentlichungen
- Alter der letzten Veröffentlichungen
- Wie lange der Autor bereits offiziell als Autor tätig ist
- Anzahl der Links, die der Content des Autors generiert
Ein Autor kann mehrere Reputation Scores je Thema haben und auch mehrere Alias z.B. je Themenbereich haben.
Viele der im Patent angegebenen Punkte beziehen sich auf eine geschlossene Plattform wie Knol. Daher soll es an dieser Stelle genügen zu diesem Patent.
Agent rank
Dieses Google Patent wurde 2005 erstmalig angemeldet und hat eine Mindestlaufzeit bis 2026. Es wurde neben den USA auch in Spanien, Kanada und weltweit angemeldet, weshalb es sehr wahrscheinlich bei der Google-Suche genutzt wird.
In dem Patent wird beschrieben, wie digitale Inhalte einem Agenten (Publisher und/oder Autor) zugewiesen werden. Diese Inhalte werden unter anderem basierend auf einem Agent Rank gerankt. Der Agent Rank ist unabhängig von der Suchintention einer Suchanfrage und wird auf Basis der dem Agent zugewiesenen Dokumente und deren Backlinks ermittelt.
Der Agent Rank kann sich ausschließlich auf eine Suchanfrage, Suchanfragen-Cluster oder ganze Themenfelder beziehen.
“The agent ranks can optionally also be calculated relative to search terms or categories of search terms. For example, search terms (or structured collections of search terms, i.e., queries) can be classified into topics, e.g., sports or medical specialties, and an agent can have a different rank with respect to each topic.”
Google Patent US20070033168A1
Credibility of an author of online content
Dieses Google Patent wurde 2008 zum ersten Mal angemeldet und hat eine Mindestlaufzeit bis 2029. Es wurde bisher nur in den USA angemeldet. Es wurde genauso wie das Patent “Reputation Score of an author” von Justin Lawyer entwickelt und hat einen direkten Bezug zur Anwendung in der Suche.
In dem Patent findet man u.a. ähnliche Punkte wie im oben genannten Patent.
Für mich ist es das spannendste Patent mit Blick auf die Bewertung von Autoren hinsichtlich Trust und Autorität. Denn in diesem Patent wird auf verschiedene Faktoren verwiesen, mit denen die Glaubwürdigkeit eines Autors algorithmisch ermittelt werden kann.
Es beschreibt, wie eine Suchmaschine Dokumente unter Einfluss eines Kredibilitäts-Faktors und Reputations-Score des Autors ranken kann.
In diesem Patent gibt es auch wieder einen Hinweis auf Links als möglichen Faktor für eine E-E-A-T-Bewertung. So kann der Reputation-Score eines Autors durch die Anzahl der Verlinkungen der veröffentlichten Inhalte beeinflusst werden.
Es werden folgende mögliche Signale für einen Reputation-Score genannt:
- wie lange der Autor bereits nachweislich Content in einem Themenbereich produziert
- Bekanntheitsgrad des Autors
- Bewertungen der veröffentlichten Inhalte durch Nutzer
- Veröffentlichung der Inhalte des Autors von einem Publisher mit überdurchschnittlichen Bewertungen
- Anzahl der durch den Autor veröffentlichten Inhalte
- wie lange die letzte Veröffentlichung des Autors her ist
- Bewertungen bisheriger Veröffentlichungen ähnlichen Themas des Autors
Weitere interessante Informationen zum Reputation-Score aus dem Patent:
- Ein Autor kann mehrere Reputation-Scores haben, je nachdem wie vielfältig die Themenbereiche seiner Publikationen sind.
- Der Reputation-Score eines Autors ist unabhängig vom Publisher.
- Der Reputation-Score kann zurückgestuft werden, wenn Duplikate von Inhalten oder Auszüge mehrfach veröffentlicht werden.
- Der Reputation-Score kann durch die Anzahl der Verlinkungen der veröffentlichten Inhalte beeinflusst werden.
Des Weiteren wird in dem Patent auf einen Kredibilitäts-Faktor für Autoren eingegangen. Folgende Einflussfaktoren werden genannt:
- Verifizierte Informationen zum Beruf bzw. die Rolle des Autors in einem Unternehmen. Dabei spielt auch die Kredibilität des Unternehmens eine Rolle.
- Relevanz des Berufs zu den Themen der veröffentlichten Inhalte.
- Bildungsgrad und Ausbildung des Autors
- Erfahrung des Autors aufgrund der Zeit. Je länger ein Autor bereits zu einem Themenfeld publiziert, desto glaubwürdiger ist er. Über das Datum der Erstpublikation in einem Themenfeld lässt sich für Google die Erfahrung des Autors/Publishers algorithmisch feststellen.
- Anzahl der zu einem Thema veröffentlichten Inhalten. Veröffentlicht ein Autor viele Beiträge zu einem Thema, kann davon ausgegangen werden, dass er ein Experte ist und eine gewisse Glaubwürdigkeit besitzt.
- Vergangene Zeit bis zur letzten Veröffentlichung. Je länger die letzte Publikation eines Autors zu einem Themenfeld her ist, desto mehr sinkt ein möglicher Reputations-Score zu diesem Themenfeld. Je aktueller die Inhalte sind, desto höher ist dieser.
- Nennungen des Autors / Publishers in Award- und Best-of-Listen
Systems and methods re-ranking ranked search results
Dieses Google Patent wurde 2013zum ersten Mal angemeldet und hat eine Mindestlaufzeit bis 2033. Es wurde bisher in den USA und weltweit angemeldet, was eine Nutzung durch Google wahrscheinlich macht. Zu den Erfindern des Patents gehört Chung Tin Kwok, der an mehreren E-E-A-T-relevanten Google Patenten beteiligt war.
In dem Patent wird beschrieben, wie Suchmaschinen neben den Verweisen zu Inhalten des Autors auch der Anteil, den er zu einem thematischen Dokumenten-Korpus beitragen kann, für ein Autoren-Scoring berücksichtigt werden kann.
„In some embodiments, the determining the original author score for the respective entity includes: identifying a plurality of portions of content in the index of known content identified as being associated with the respective entity, each portion in the plurality of portions representing a predetermined amount of data in the index of known content; and calculating a percentage of the plurality of the portions that are first instances of the portions of content in the index of known content.“
Google Patent US10204145B2
Es beschreibt ein Re-Ranking von Suchergebnissen nach einem Autoren-Scoring inkl. einem Citation-Scoring. Das Citation-Scoring basiert auf der Anzahl der Verweise auf die Dokumente eines Autors. Ein weiteres Kriterium für das Autoren-Scoring ist der Anteil der Inhalte, die ein Autor zu einem Korpus an themenrelevanten Dokumenten beigesteuert hat.
„wherein determining the author score for a respective entity includes: determining a citation score for the respective entity, wherein the citation score corresponds to a frequency at which content associated with the respective entity is cited; determining an original author score for the respective entity, wherein the original author score corresponds to a percentage of content associated with the respective entity that is a first instance of the content in an index of known content; and combining the citation score and the original author score using a predetermined function to produce the author score;“
Google Patent US10204145B2
Das Patent hat eigentlich den Hintergrund, “Copycats” zu identifizieren und deren Inhalte in den Rankings downzugraden, kann aber auch für die generelle Bewertung von Autoren genutzt werden.
Faktoren für die Bewertung eines Autors
Neben den in den genannten Patenten aufgeführten möglichen Faktoren für eine Autoren-Bewertung, möchte ich nachfolgend noch weitere nennen, die ich teilweise bereits in meinem Artikel 18 E-E-A-T-Bewertungs-Faktoren für das Ranking bei Google genannt habe.
- Qualität des Contents zu einem Themenbereich in Summe: Die Qualität, die ein Autor über seine Inhalte zu einem Themenbereich in der Gesamtheit Domain- und Format-unabhängig liefert, kann ein Faktor für E-E-A-T sein. Signale hierfür können Nutzersignale, Links und andere Qualitätssignale auf Inhaltsebene sein.
- PageRank bzw. Referenzen zu Inhalten des Autors
- Kookkurrenzen des Autors in Inhalten (Podcasts, Videos, Websites, PDFs, Büchern …) mit relevanten Themen bzw. Begriffen
- Kookkurrenzen des Autors in Suchanfragen mit relevanten Themen bzw. Begriffen
Fazit
Machine Learning Methoden wie Natural Language Processing über Embeddings machen es möglich, im großen Stil semantische Strukturen aus unstrukturierten Inhalten zu erkennen und abzubilden. Dadurch kann Google noch viel mehr Entitäten erkennen und verstehen als im Knowledge Graph bisher abgebildet sind.
Dadurch spielt die Quelle eines Inhalts eine immer größere Rolle und das E-E-A-T-Konzept kann algorithmisch nicht nur auf Dokumente / Inhalte und Domains angewendet werden, sondern auch auf die Urheber-Entitäten von Inhalten. Also den Autoren und Organisationen, die verantwortlich für den Content sind.
Ich denke, wir werden in den nächsten Jahren einen noch größeren Einfluss von E-E-A-T auf die Google-Suche sehen. Dieser Faktor wird mindestens genauso wichtig für das Ranking sein wie die Relevanz-Optimierung von einzelnen Inhalten.