
Wie viele Suchmaschinenoptimierer auch, habe ich mir Anfang August die Frage gestellt, ob der Ranking-Bug beziehungsweise Indexierungs-Glitch von Google eventuell Vorbote eines neuen Updates sein könnte oder ob man aus den Rankingveränderungen irgendeine Erkenntnis in Sachen Optimierung gewinnen kann.
Wahrscheinlich habt ihr es mitbekommen, aber für diejenigen unter Euch, die Googles Bewegungen nicht auf Schritt und Tritt verfolgen, hier nochmal eine Zusammenfassung:
Anfang August gab es einen massiven Anstieg in der Fluktuation der Suchergebnisse bei Google und das weltweit und in allen Sprachen. In den Webmaster-Foren wie auch in den üblichen Black Hat Foren wurde sofort über den Rollout eines massiven unangekündigten Updates gemutmaßt.
Die Schwankungen bzw. Veränderungen innerhalb der Suchergebnistreffer waren dabei so massiv, dass mehrere große SEO-Portale in den USA sogar vom größten Update aller Zeiten berichteten.
Tatsächlich haben alle SEO-Tools und Ranking Checker angeschlagen und es kam tatsächlich in einem kurzen Zeitpunkt zu massiven Verschiebungen innerhalb der Suchergebnisse von Google. Die Suchergebnisse waren allerdings nicht nur verändert, sondern offensichtlich -durcheinandergeraten, teilweise mit absurden Ergebnissen auf den vordersten Plätzen.
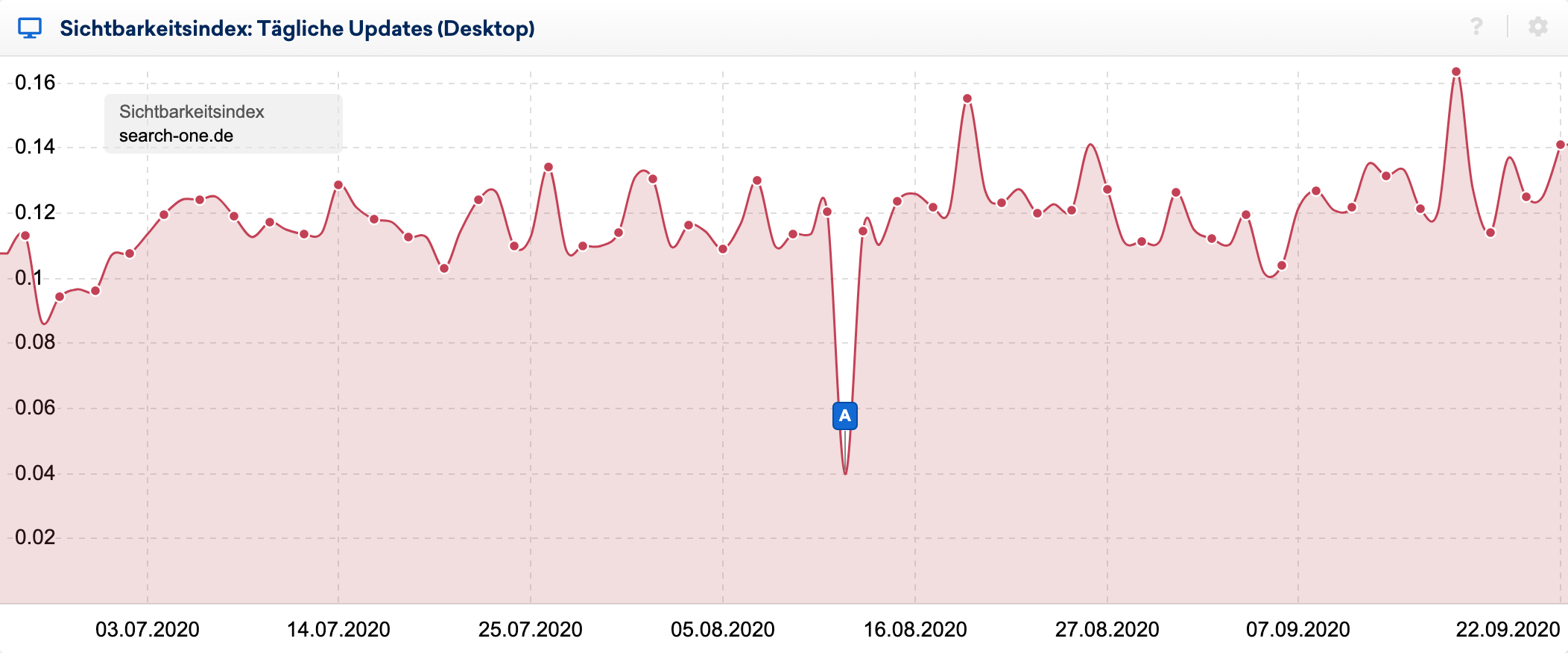
Man sieht die Auswirkungen des Bugs sehr schön im Verlauf des Sichtbarkeitsindex beim täglichen Verlauf:
Mit der großartigen Funktion des SERP-Vergleichs in der SISTRIX Toolbox habe ich mir die Veränderungen innerhalb der Top 20 einiger Keywords genauer angesehen, deren Rankings ich bereits seit vielen Jahren beobachte. Zu diesen Keywords habe ich dutzende Analysen der rankenden Webseiten durchgeführt und weiß in aller Regel relativ gut, wieso eine URL dort rankt, wo sie eben rankt.
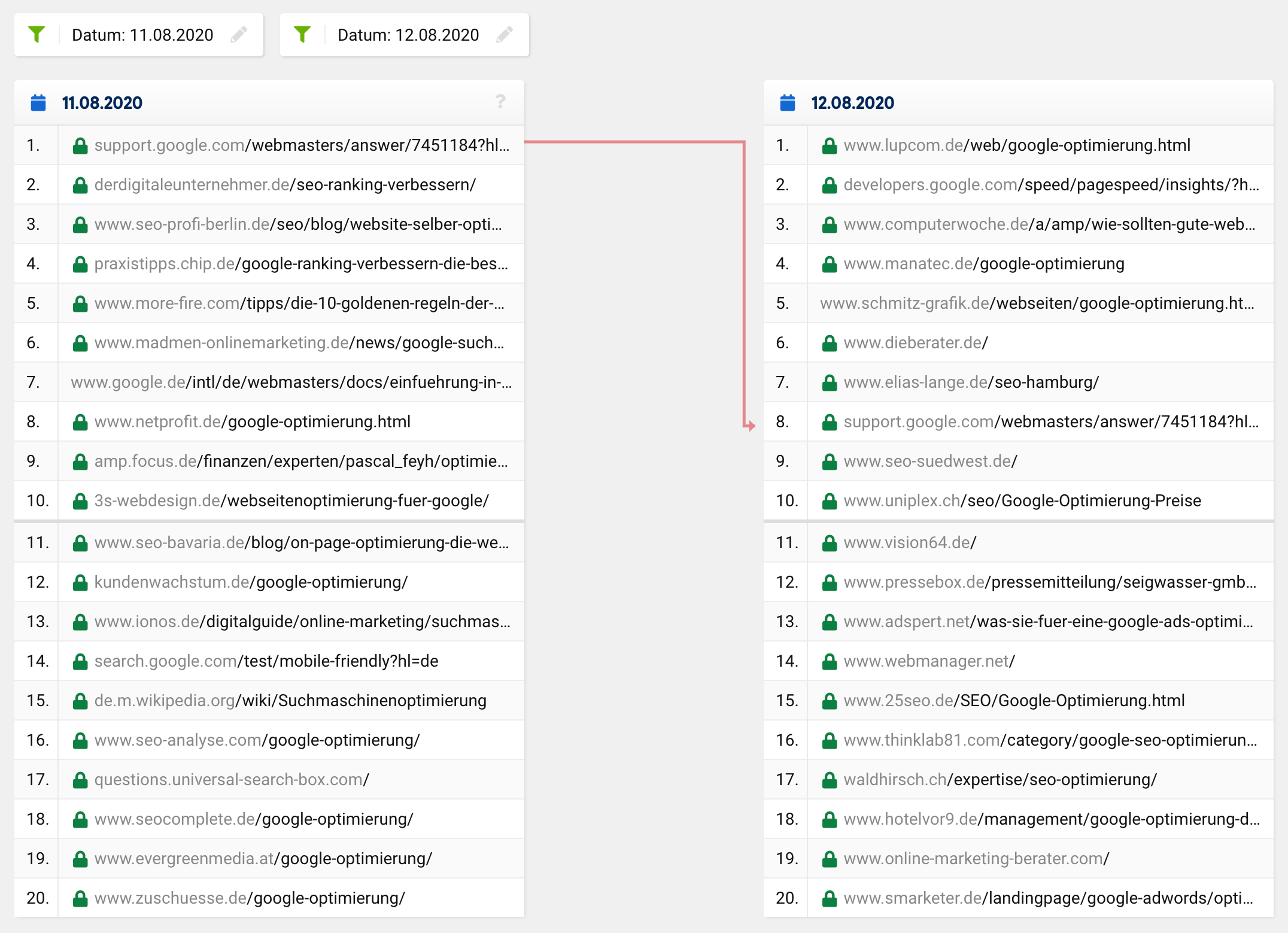
Schaut man sich einmal den SERP-Vergleich für das Keyword „google optimierung“ zum betroffenen Zeitpunkt an, sieht man, dass sich die gesamte Top 20, mit Ausnahme einer URL komplett verändert hat. Der vorherige Platz 1 rutschte auf Platz 8 ab, die restlichen URLs kommen quasi „aus dem Nichts“ also außerhalb der Top 20 auf die vordersten Plätze.
Ein normales Update bzw. eine normale Rankingveränderung hingegen sieht eher so aus:
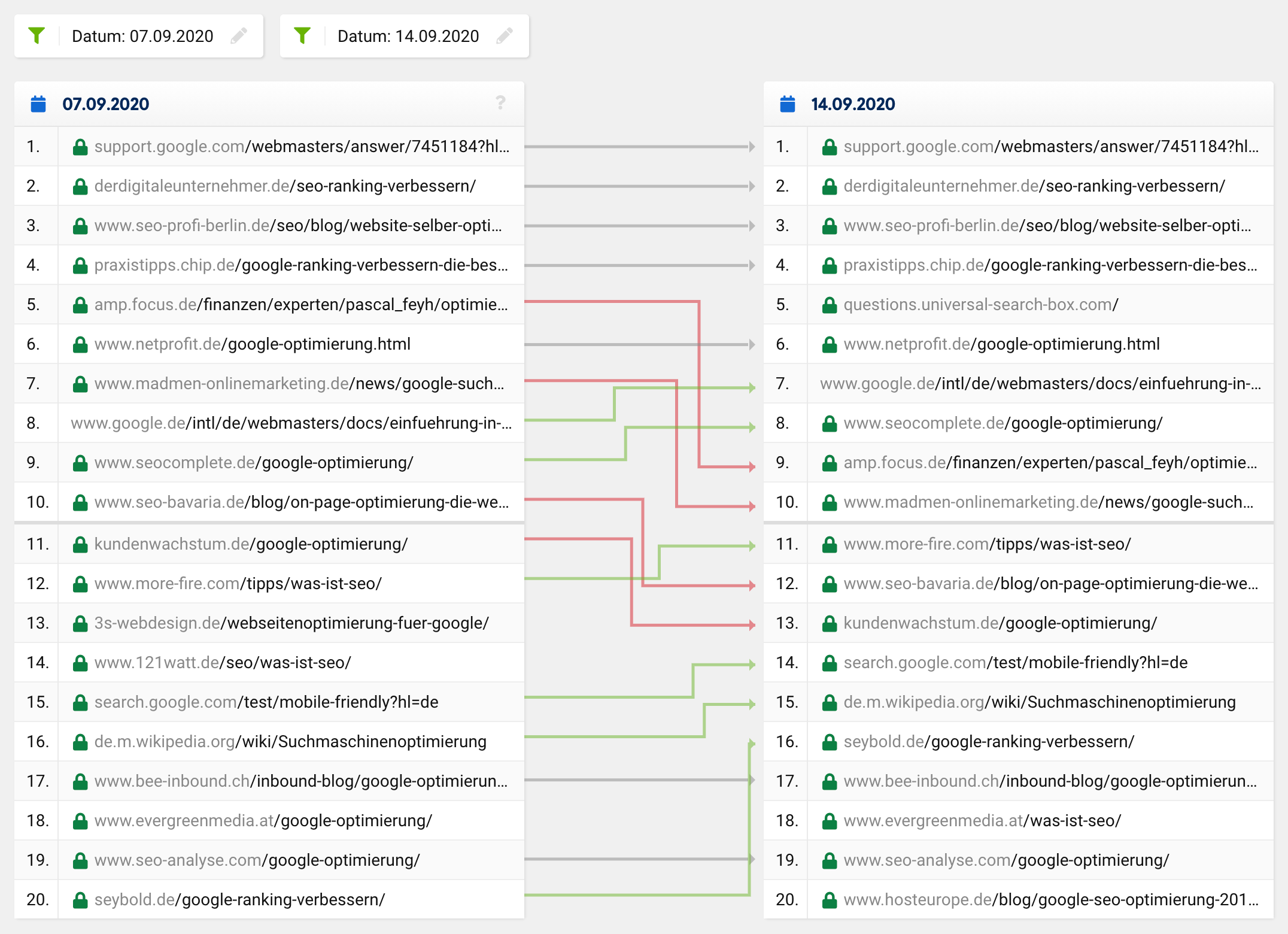
Viele URLs bleiben stabil und es gibt einzelne URLs die gewinnen während andere URLs Positionen verlieren. Selbstverständlich fliegt auch mal eine URL aus den Top 20 oder taucht neu darin auf, jedoch ist es absolut unüblich, dass von 20 Treffern nur noch ein einziger in der „neuen“ Top 20 übrig bleibt und das nicht bei einem einzigen Keyword, sondern auf breiter Front.
Bei derart tiefgreifenden Veränderungen könnte man natürlich, ähnlich wie bei den berühmt berüchtigten Phantom-Updates auch von einer Justierung des angenommenen User Intents einer Suchanfrage ausgehen, was dann eben auf einigen Keywords zu grundlegenden Veränderungen in der Zusammensetzung der Top 20 führen würde.
Doch in diesem Fall würden die Suchergebnisse sich doch verbessern, also relevanter und sinnvoller werden, was aus meiner Sicht bei diesem Glitch definitiv nicht der Fall ist.
Die allermeisten SEOs wunderten sich über die offensichtlich absurden Suchergebnisse und gingen relativ schnell von einem Fehler aus – oder hofften zumindest, dass es sich bloß um ein vorübergehendes Problem handle. Mir ging es ebenso, verloren einige meiner Webseite an diesem Tag ihre wichtigsten Rankings komplett!
Böser Schreck: Es war nur ein Fehler!
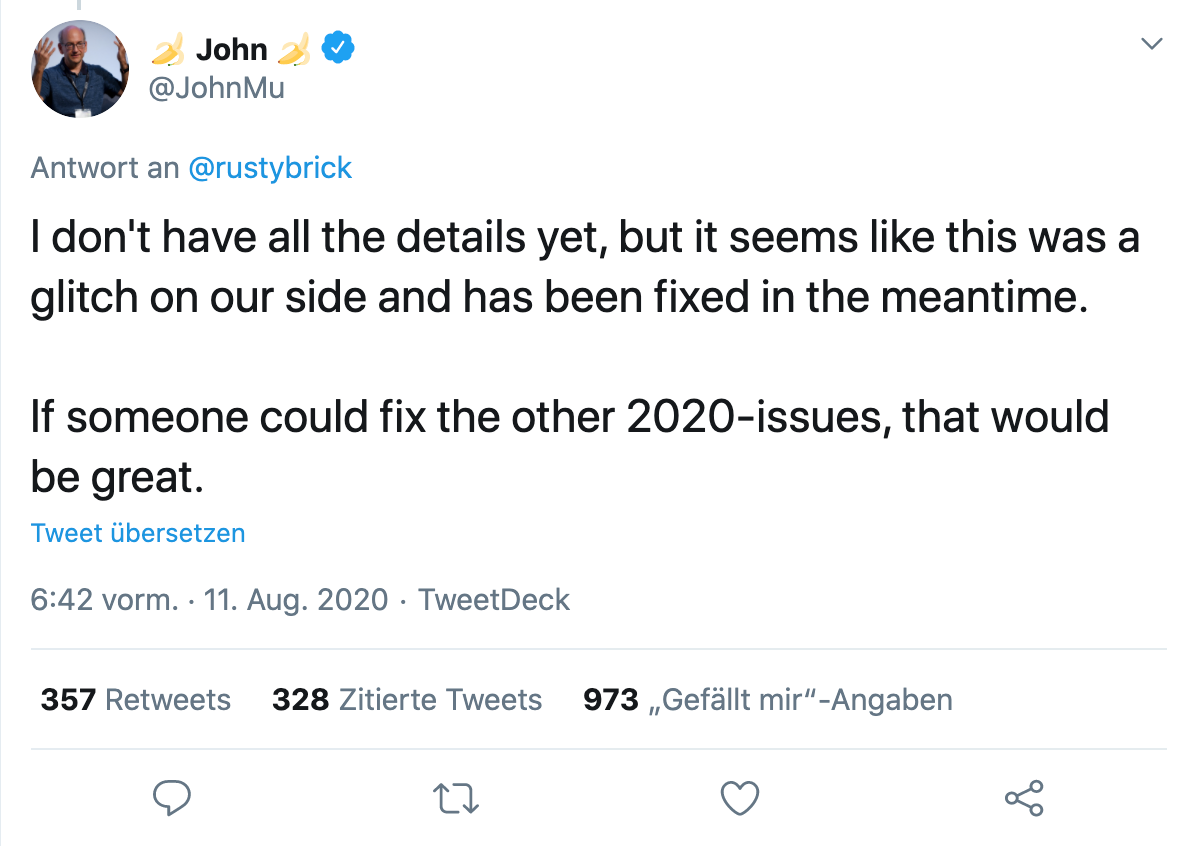
Noch in derselben Nacht bestätigte ein Google-Sprecher, dass es sich um einen Fehler handelt, den sie beheben und ein paar Stunden später war wieder alles wie zuvor. John Müller bestätigte per Twitter, dass der Bug gefixt wurde, ihm jedoch noch nicht alle Details vorlägen:
Und einen Tag später kam die Bestätigung des offiziellen Google Webmasters Accounts, dass es sich offenbar um ein Problem mit dem Indexierungssystems gehandelt hat, welches die Suchergebnisse beeinflusst hatte.
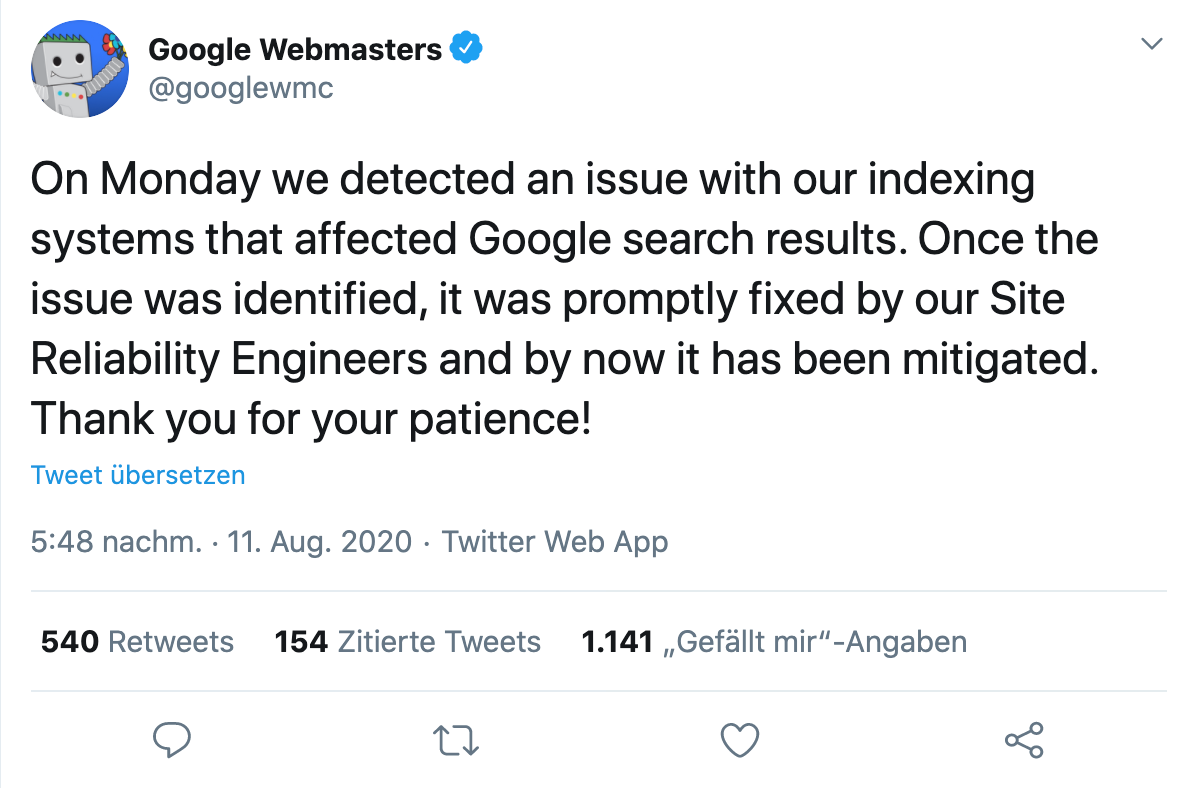
Und hier begannen die Mutmaßungen, was genau passiert sein könnte.
Gary Illyes versuchte die Sache ein bisschen konkreter zu machen und beschrieb, wofür das Indexierungssystem, Caffeine zuständig ist. Laut seinem Tweet liest es die Abrufprotokolle ein, rendert und konvertiert die abgerufenen Daten, extrahiert Links, Meta- und strukturierte Daten, extrahiert und berechnet einige ungenannte Signale, plant neue Crawls und baut anschließend den Index auf, der dann für die Ausgabe in den Suchergebnissen bereitgestellt wird.
Zum besseren Verständnis gab er einige Beispiele, was dabei schief gehen könnte, das sich dann in der Veränderung der Suchergebnisse auswirken könnte:
Wenn die Planung der Crawls schief geht, kann das das Crawling verlangsamen. Wenn das Rendern schief geht, könnte Google die Seiten fehlinterpretieren. Wenn die Indexerstellung schief geht, kann das Ranking und die Bereitstellung der Suchergebnisse beeinträchtigen.
– Gary Illyes
Er betonte anschließend wie komplex die Suche doch sei und dass Tausende von miteinander verbundenen Systemen fehlerfrei zusammenarbeiten müssen, um den Nutzern relevante Ergebnisse zu liefern. Wenn man dort irgendwo ein Sandkorn ins Getriebe wirft, käme es eben zu einem Ausfall wie gestern.
Auf Nachfrage eines Twitter-Nutzers, konkretisierte er, dass es offenbar zu einem Fehler bei der Erstellung des Index selbst kam:
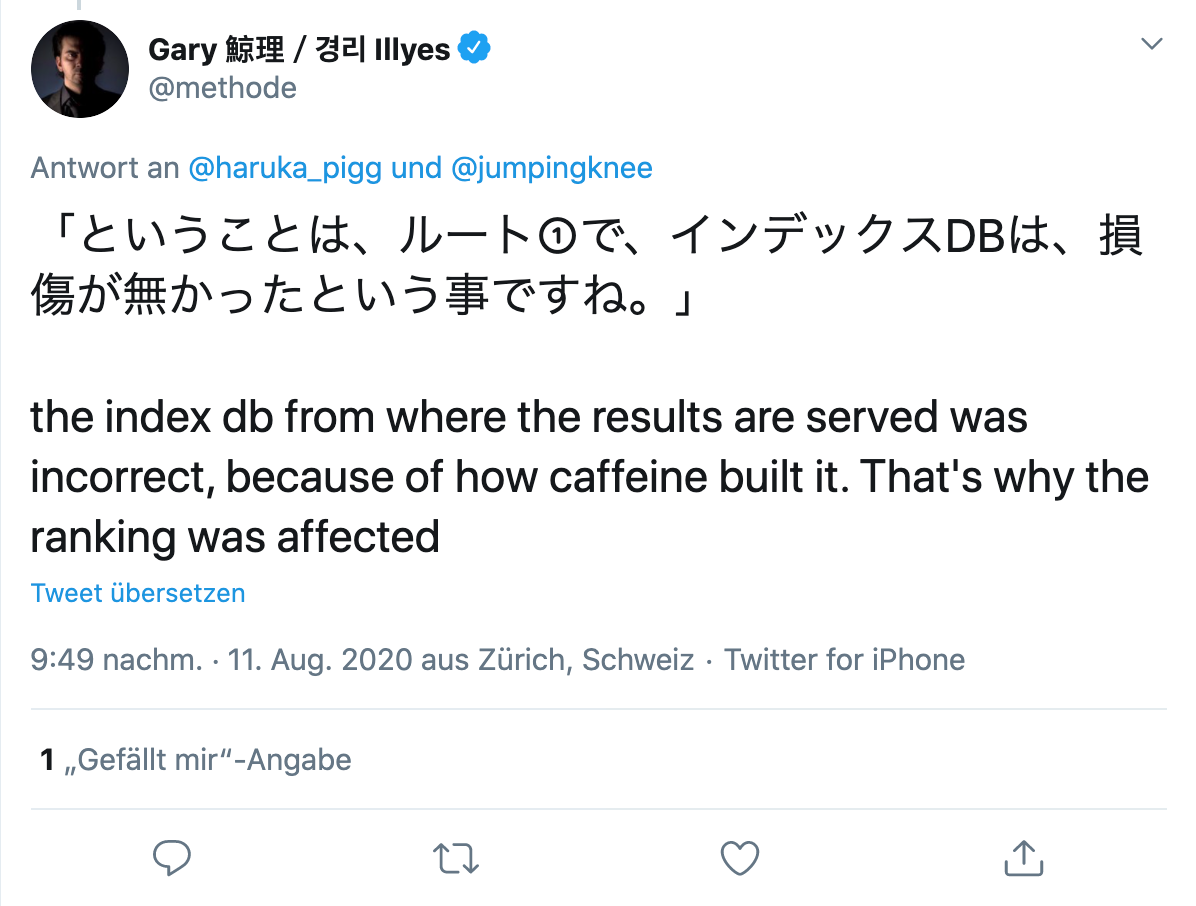
Wo ist denn dann das Problem?
Der Bug an sich ärgert mich nicht, schließlich ging es um einen Zeitraum von wenigen Stunden und das Problem wurde seitens Google schnell behoben, allerdings sind mir einige Äußerungen und Veröffentlichungen hierzu im Nachhinein sehr sauer aufgestoßen.
Denn, obwohl Google relativ transparent das Problem offengelegt hatte, versuchten sich einige SEOs auf Biegen und Brechen einen Reim aus dem Bug zu machen und begannen die Veränderungen nach irgendwelchen Mustern zu untersuchen.
Ein Mitarbeiter bzw. eine Mitarbeiterin einer bekannten Amerikanischen SEO-Agentur, die ich an dieser Stelle nicht an den Pranger stellen möchte, begann die Google Analytics Daten jedes derzeitigen und ehemaligen Kundens auszuwerten und versuchte daraus Rückschlüsse auf den Grund für die Rankingveränderungen zu ziehen.
Das halte ich aus mehreren Gründen für mehr als grenzwertig, aber dazu später mehr.
Was fand der/die Mitarbeiter*in über den Glitch heraus?
Bei regulären Google-Updates wären bei betroffenen Kunden meist alle Unterseiten einer Domain von der Veränderung betroffen, egal ob positiv oder negativ. Dies sei beim aktuellen Glitch nicht der Fall, denn während bei ein und derselben Domain manche Unterseiten massive Verluste hinnehmen mussten, konnten andere hingegen gewinnen und wiederum andere hätten sich gar nichts oder kaum etwas verändert.
Seine bzw. ihre erste Erkenntnis lautet daher: Es sieht nicht wie ein typisches Google Update aus. Soweit gehe ich noch konform.
Nun wird es jedoch etwas abenteuerlich:
„Viele Seiten, die sich verbessert haben, enthielten medizinische Informationen, die dem wissenschaftlichen Konsens widersprechen. Zur Erklärung wird hier auf die Google Quality Rater Guidelines verwiesen und dass diese bei der Bestimmung von E-A-T einer Seite zu wissenschaftlichen Themen von Menschen oder Organisationen mit fachlicher Expertise im jeweiligen Gebiet erstellt werden sollten und den etablierten Konsens der Wissenschaft widerspiegeln sollte, insofern ein solcher existiere.“
„Belegt“ wird diese Behauptung mit der Beobachtung, dass einige wenige medizinische Artikel, die dem Stand der Wissenschaft offensichtlich widersprechen und dazu noch schlechte oder unnatürliche Backlinks haben, plötzlich sehr viel besser gerankt hätten, als vor und nach dem Bug.
Deren Theorie lautet schlussendlich, dass Seiten gut gerankt haben, die eigentlich wegen Qualitätsproblemen abgewertet werden sollten. Beispielsweise wären gehackte Seiten, Seiten mit unnatürlichen Links oder eben Seiten mit vom allgemeinen wissenschaftlichen Konsens abweichenden Behauptungen in Top-Positionen katapultiert worden.
Daraus lautet der oder die Autor*in folgendes ab:
Wenn sich die Rankings einer Seite verbessert haben, wäre das vielleicht ein Grund zur Freude und vielleicht handle es sich um einen schiefgelaufenen Test eines zukünftigen Updates. Oder aber es könnte ein Hinweis auf ein Qualitätsproblem der Webseite haben, welches das Rankingpotential der Seite begrenze, in der Zeit des Bugs jedoch kurzzeitig keine Rolle mehr gespielt haben könnte.
Auf der anderen Seite, also wenn eine Seite Rankings verloren hatte, könnte das bedeuten, dass man durch minderwertige oder spammige Seiten im Ranking überholt wurde, die nun wieder von Googles Algorithmen unterdrückt bzw. abgestuft werden.
Uffz! Really? Was soll mir diese Erkenntnis denn nun für meine tägliche SEO-Arbeit bringen?!
Wieso sollte man keine derartigen Analysen durchführen?
Abgesehen davon, dass die Google Analytics Daten ehemaliger Kunden genutzt wurden, sehe ich hier ein sehr viel größeres Problem bei der Vorgehensweise des Mitarbeiters:
Das Problem dabei ist, dass wenn man ohne eine Hypothese nach irgendwelchen Mustern sucht, wird man immer fündig. Wenn man diese damit jedoch damit alleine als korrekt ansieht, hat das jedoch nichts mit Wissenschaft zu tun.
Es ergeben sich immer irgendwelche Muster, manchmal zufällig, manchmal durch einen oder mehrere Faktoren, die diese Muster erzeugen. Man kann nicht erst nach Mustern suchen und dann sich eine Theorie dazu überlegen, die das Beobachtete erklärt und diese als Tatsache verkaufen. So funktioniert Erkenntnis einfach nicht.
Ich wünsche mir an dieser Stelle wirklich etwas mehr wissenschaftliche Methoden im SEO, beispielsweise wenn es darum geht, Hypothesen aufzustellen und diese anschließend zu testen!
Was ist eine Hypothese und wie stellt man diese richtig auf?
Eine Hypothese ist eine begründete Vermutung, die man zu Beginn einer empirischen Untersuchung aufstellt. Diese Annahme wird mittels qualitativer oder quantitativer Methoden analysiert und anschließend bestätigt oder widerlegt.
Beim Aufstellen einer Hypothese geht man entweder von einem Zusammenhang oder von keinem Zusammenhang zwischen zwei Variablen aus. Eine unabhängige Variable ist dabei die Ursache, die abhängige die möglicherweise eintretende Wirkung.
Grundsätzlich gibt zwei Arten von Hypothesen: Ungerichtete und gerichtete Hypothesen.
Bei einer ungerichteten Hypothese vermutet man lediglich einen Zusammenhang zwischen zwei Variablen. Beispielsweise: Die Anzahl verlinkender Webseiten beeinflusst die Sichtbarkeit einer Domain.
In der gerichteten Hypothese bewertet man hingegen den vermuteten Zusammenhang. Beispielsweise: Je mehr Backlinks ein Artikel hat, desto besser rankt dieser.
Um eine Hypothese aufstellen zu können, müssen allerdings stets folgende Kriterien beachten werden:
- Beide verwendeten Variablen müssen messbar sein.
- Hypothesen müssen sachlich-objektiv und prägnant formuliert sein.
- Formuliert man mehrere Hypothesen, dürfen diese einander nicht widersprechen.
- Und: Wissenschaftliche Annahmen müssen sich widerlegen lassen.
Und hier kommen wir zum größten Problem: Da sich die meisten Annahmen im Bereich SEO schlicht nicht sauber durch ein Experiment widerlegen lassen, kann man aus wissenschaftlicher Sicht hier von keinen Erkenntnissen sprechen. Die aufgestellte Hypothese müsste falsifizierbar sein und daher in einem kontrollierten Experiment überprüft werden können.
Daher sollte man auch nicht einfach die Ergebnisse zu irgendwelchen Suchanfragen analysieren, um daraus auf die eingesetzten Rankingfaktoren zu schließen.
Leider ist es sehr schwierig, eine saubere und kontrollierte Umgebung für SEO-Experimente zu schaffen, die ohne störende Variablen auskommen. Und falls man das doch hinbekommt, lassen sich die erzielten Erkenntnisse meist nicht auf die echte Welt und reale Suchergebnisse verallgemeinern.
Die Erkenntnis das Korrelation nicht gleich Kausalität bedeutet, hat sich glücklicherweise in den letzten Jahren durchgesetzt. Studien zu Rankingfaktoren irgendwelcher Toolanbieter nimmt kein gestandener SEO heute mehr ernst, wodurch immer weniger davon werden durchgeführt und veröffentlicht werden.
