
Eigentlich ist das Thema keinen eigenen Blogpost wert, aber für die paar Twitter-Zeichen dann doch wieder zu lang. Die großen Suchmaschinen (ließ: „Google“) haben vor einiger Zeit die Möglichkeit eröffnet, Anweisungen an den Crawler nicht nur in einen Meta-Tag, sondern auch in den HTTP-Header zu packen. Hier hatte ich zu dem Thema mal etwas geschrieben. Das funktioniert im Prinzip auch wunderbar, ich nutze das Feature gerne und häufig.
Heute ist mir jedoch aufgefallen, dass die Umsetzung wohl nicht so ganz sauber implementiert ist: während Anweisungen wie „noarchive“ problemlos umgesetzt werden, ignoriert Google ein „noodp“, das dafür sorgen soll, dass das Snippet aus dem Seiteninhalt und nicht mit dem Dmoz-Text erstellt werden soll. Schön sehen kann man das hier im Blog, zuerst die HTTP-Header mit der X-Robots-Anweisung:
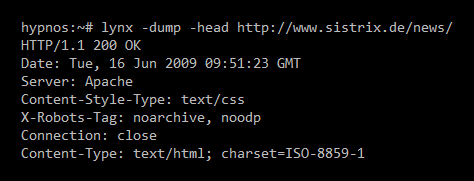
Und hier das aktuelle Snippet aus den Google-SERPs zu SEO-Blog mit dem Text aus dem Dmoz:
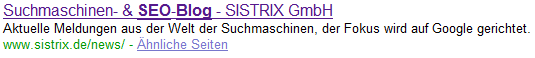
Fehler oder gewollt? Mir fällt jedenfalls kein plausibler Grund für zweitere Möglichkeit ein.