
… zumindest temporär – man möge mir die click-baity Überschrift verzeihen 😉 In diesem Artikel möchte ich zum einen die Hintergründe erläutern, die dazu geführt haben und zum anderen unser Vorgehen zur Diagnose und Behebung darstellen.
Achtung: Ziemlich ausführlich – bei wenig Zeit gerne direkt zum tl;dr springen.
- 30% down – Houston, wir haben ein Problem
- Diagnose
- Analyse des SEO Traffics
- Analyse von externen Daten
- Ist das ein Sonderfall oder können wir ein Pattern ableiten?
- Wie verhalten sich andere Webseiten, die in mehreren Ländern aktiv sind?
- Warum sollte Google eine „andere“ URL im Cache anzeigen?
- Analyse der Daten der Search Console
- Re-Evaluierung von Tickets aus den letzten Deployments im Shop
- Ticket: „Googlebot for Smartphones currently not recognized“
- Ticket: „Homepage Go-Live“
- Die Sache mit der Konsistenz
- Dem Problem auf der Spur
- „Lösung“ und Status Quo
- Fazit
- Wie können wir so etwas in Zukunft verhindern?
Bevor wir tiefer in das komplexe Konstrukt aus Canonicals, Hreflangs, Race Conditions und einem sehr sehr seltsamen Indexierungs- bzw. Ranking- Verhalten von Google eintauchen, erstmal zu den Fakten:
30% down – Houston, wir haben ein Problem
Der ein oder andere dürfte neben diesem Blog auch der Facebook Seite von Sistrix folgen. Dort wurde am vorletzten Freitag folgender Beitrag gepostet:
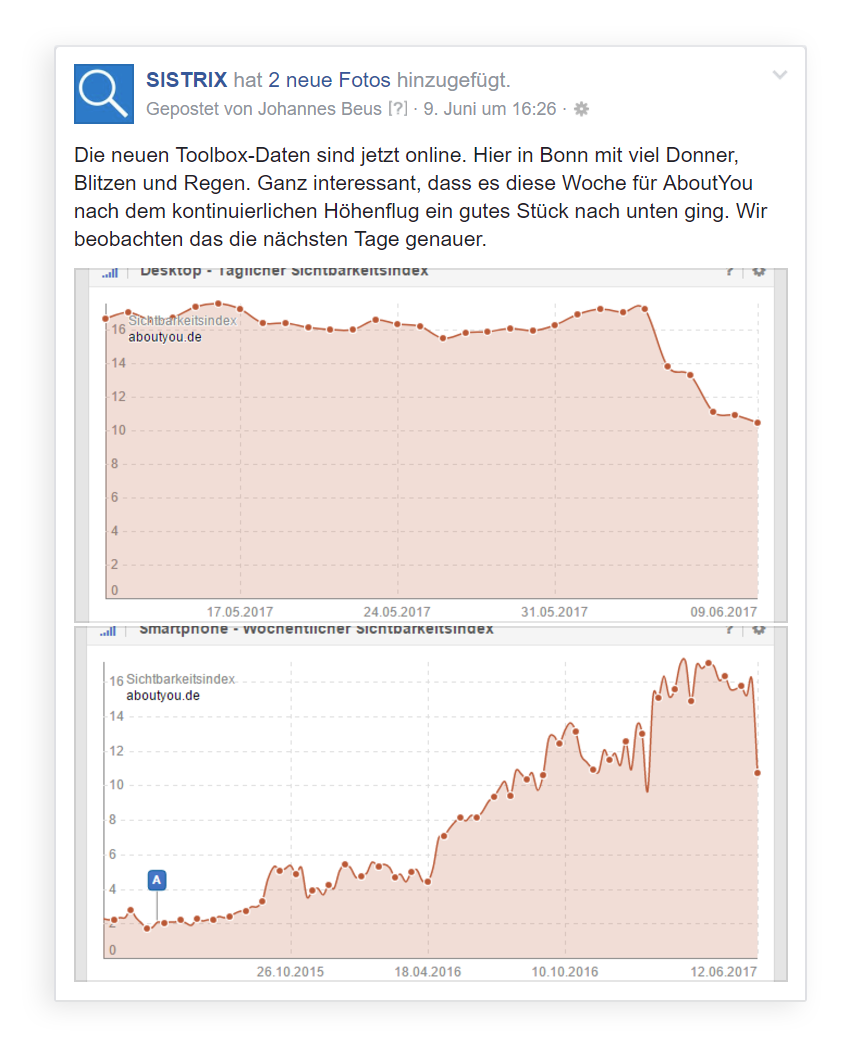
-30% Sichtbarkeit – so kann das Wochenende starten… Da wir zu diesem Zeitpunkt noch keine Gewissheit (sofern es die überhaupt gibt – dazu später mehr) über die genauen Hintergründe hatten, haben wir uns erstmal zurückgehalten.
Diagnose
Intern hatten wir die Situation seit Mittwochabend (07.06.2017) unter Beobachtung und sind am Folgetag tiefer in die Analyse eingestiegen. Bitte im Hinterkopf behalten, denn zu dem Zeitpunkt hatten wir viele Infos noch nicht (wie etwa die Sichtbarkeitsentwicklung in AT/CH).
Anhand des täglichen Sichtbarkeitsindizes zeichnete sich seit Sonntag (04.05.2017) ein Abfall der Sichtbarkeit ab:
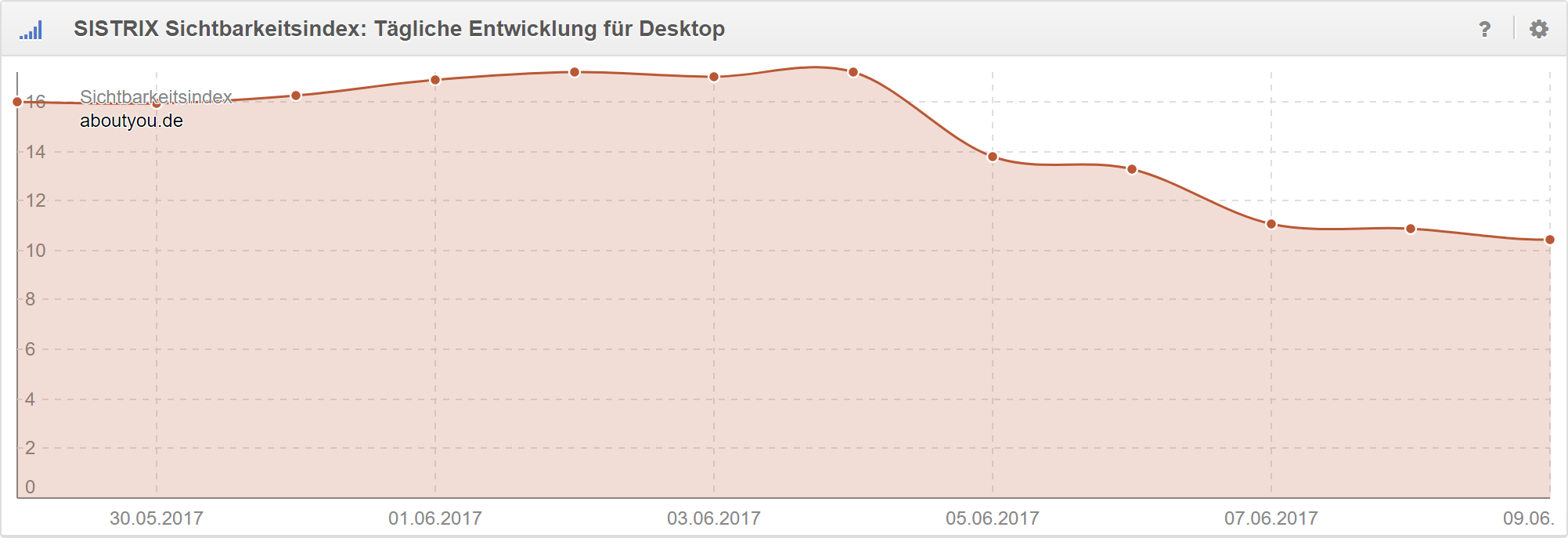
Allerdings gab es auf technischer Seite keine offensichtlichen Anzeichen für Probleme. Eindeutig wäre so etwas wie:
- Sperrung von Teilbereichen der Webseite in der robots.txt
- Großflächig falsch gesetzte Canonical / Hreflang Tags
- Falsches Ausspielen von robots noindex meta Tags
- Falsche Status Codes (non-200)
- Inkorrekte geo- oder mobile Redirects
Die Betonung liegt hier leider auf „offensichtlich“, denn bei entsprechenden Quickchecks (á la URL aufrufen und Quelltext checken) war tatsächlich alles in Ordnung (ich komme später dazu, warum das keine verlässliche Methode ist). Die Ursachenforschung ging also weiter, wobei wir uns auf folgende Bereiche konzentriert haben:
- Analyse des SEO Traffics
- Analyse von externen Daten
- Analyse der Daten der Search Console
- Re-Evaluierung von Tickets aus den letzten Deployments im Shop
Analyse des SEO Traffics
Wir setzen Google Analytics 360 als primäres Webtracking Tool bei uns ein und haben entsprechende Custom Segments zur Segmentierung einzelner Seitenbereiche eingerichtet (All, Kategorien, Produkte, etc.). Zur Eingrenzung des SEO Traffics über Google nutzen wird dazu google / organic und google / organic brand.
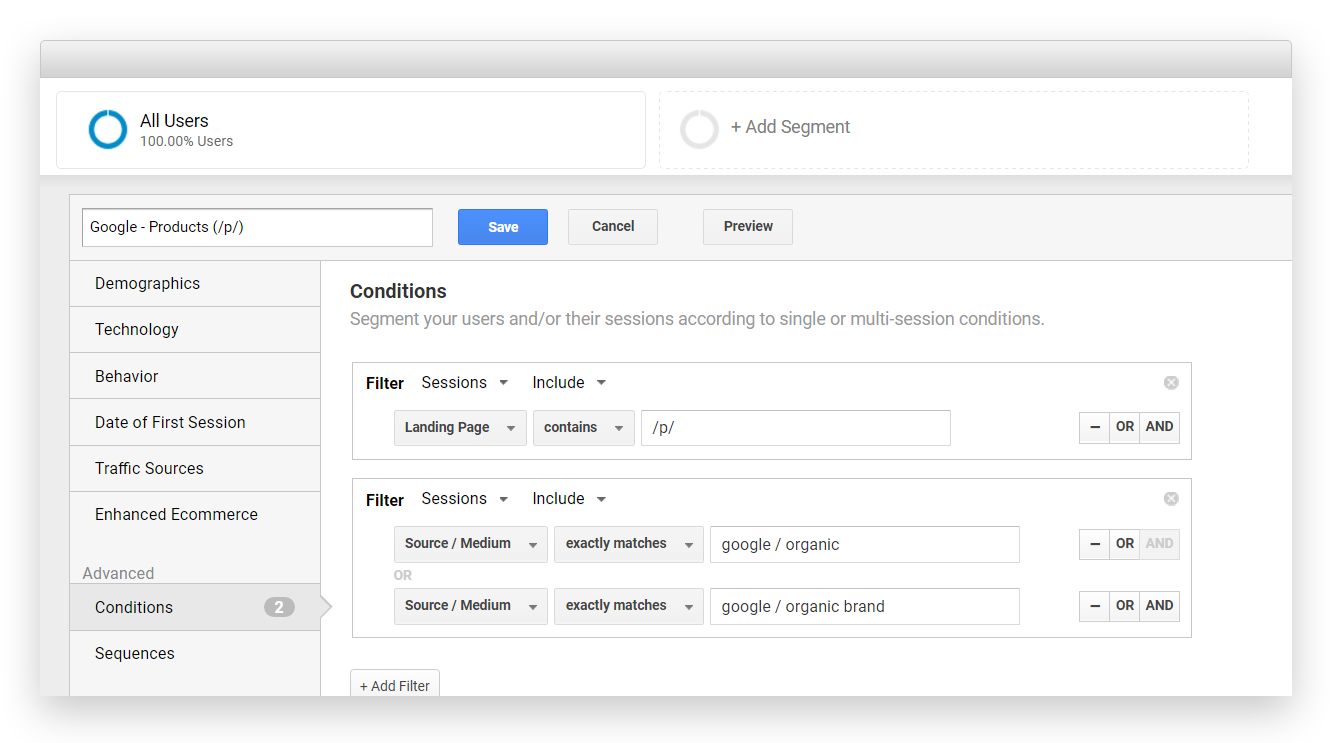
Unser SEO Reporting bilden wir über das Google Data Studio ab, da wir hier die Segmente aus Google Analytics übernehmen können und alle Seitenbereiche übersichtlich auf einen Blick vergleichen können.
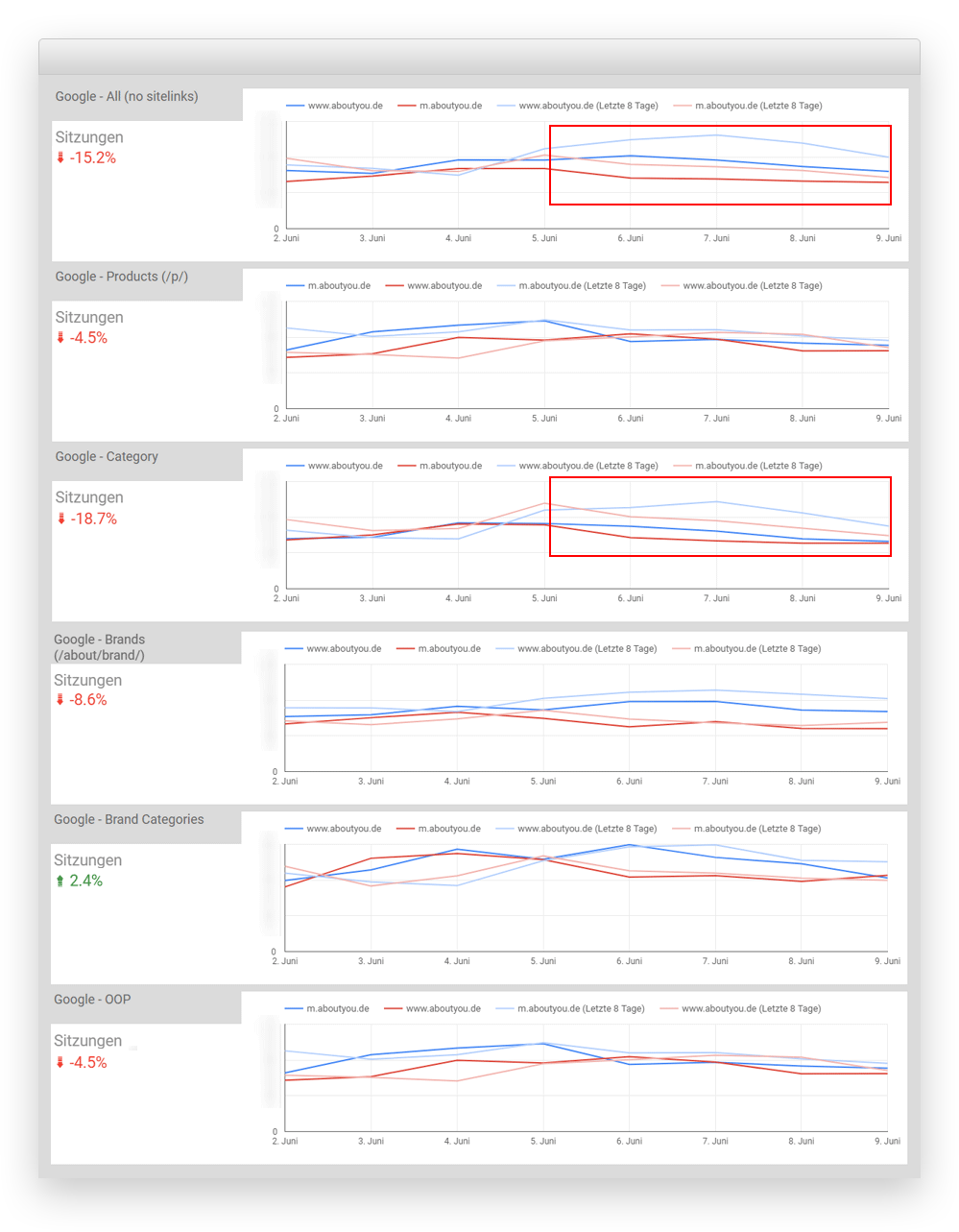
Dabei fallen zwei Dinge auf:
- Seit dem 5. Juni steigt die Differenz zur Vorwoche im Gesamt-Traffic sichtbar an (gleichfarbige, blassere Linie)
- Dieser Trend zeigt sich vor allem auf unseren Kategorieseiten (Google – Category).
Analyse von externen Daten
Um das Problem weiter einzugrenzen, haben wir uns zunächst die Keywords angeschaut, bei denen wir deutlich an Rankings verloren hatten. Oder konkret: Die verlorenen Top-20 Rankings zwischen dem 04.06.2017 und dem 08.06.2017
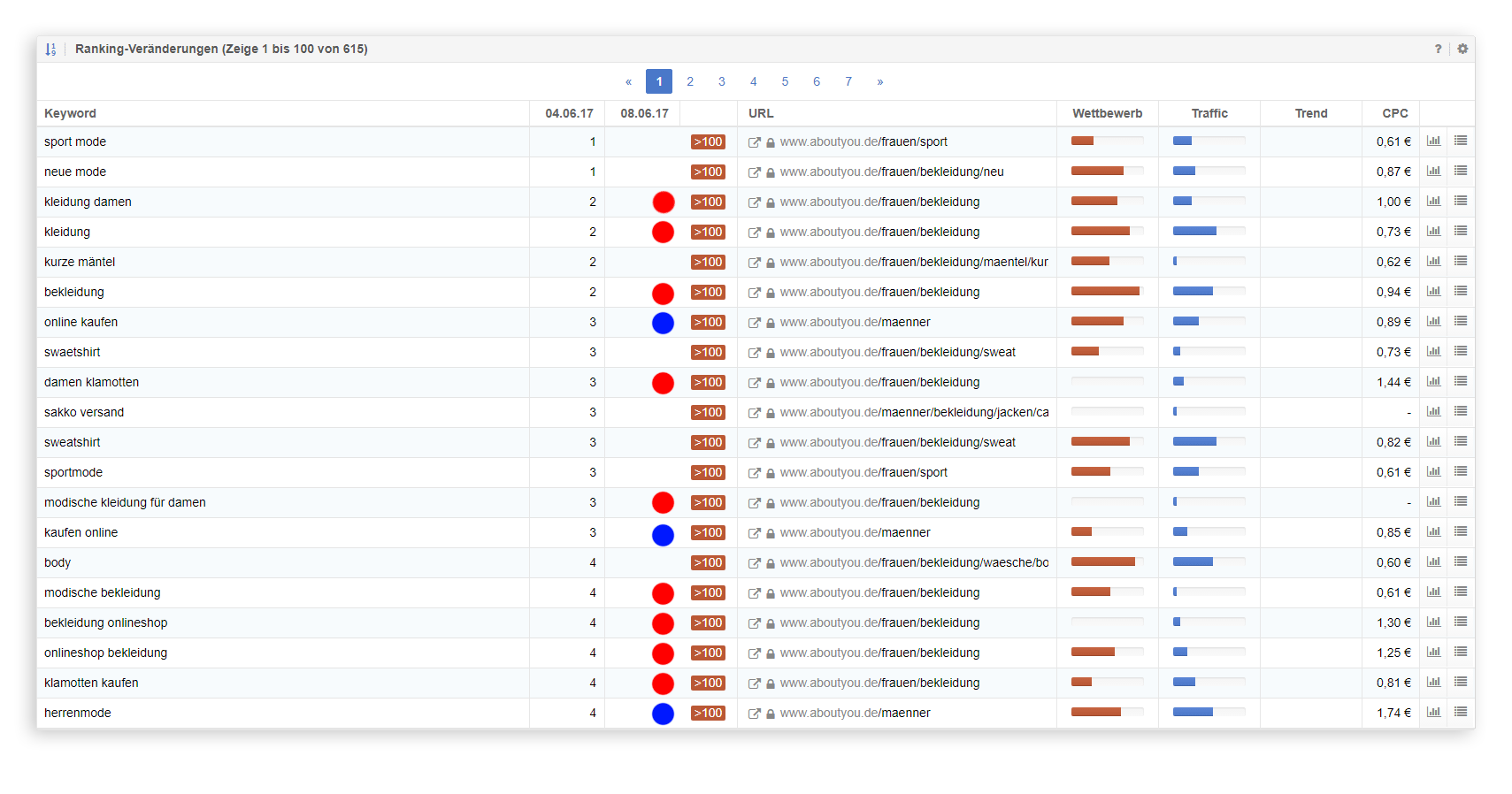
Die URLs
- www.aboutyou.de/frauen/bekleidung
- www.aboutyou.de/maenner
stechen bereits in der Übersicht hervor und das Bild deckt sich insgesamt mit unseren Traffic Daten, denn unsere Kategorien liegen unter /frauen/ bzw. /maenner/. Schaut man sich sowohl die konkreten URLs (ohne abschließenden /) als auch die Summe der Damenmode-Kategorien (alles unter /frauen/bekleidung/) im täglichen Verlauf an, sieht man den Einbruch deutlich.
Unser /about/ Segment, das hauptsächlich für unsere Marken rankt, ist zwar ebenfalls betroffen aber bei weitem nicht so stark (relativ betrachtet).
Bei der konkreten Kontrolle der verlorenen Rankings sind dann zum ersten Mal Anomalien aufgefallen. Tatsächlich waren die URLs für die generischen Suchanfragen nicht mehr auffindbar, aber durch Eingabe der konkreten URL als Suchbegriff waren sie teilweise noch „im Index“.
Ein Blick in den Cache zeigte dann zum Beispiel folgendes Bild:
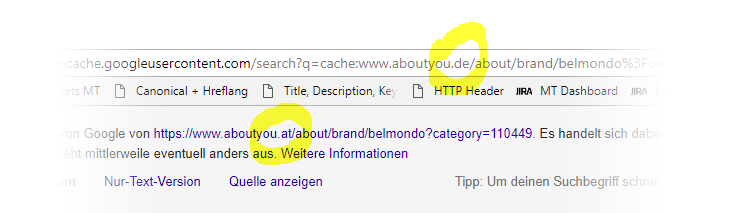
Obwohl wir im deutschen Index gesucht haben und auch eine deutsche URL gerankt hat, wird im Cache von Google die Variante unsere AT Domain angezeigt. Ab hier wurde es spannend und es gab eine Reihe „ungeklärter Fragen“:
- Ist das ein Sonderfall oder können wir ein Pattern ableiten?
- Wie verhalten sich andere Webseiten, die in mehreren Ländern aktiv sind?
- Warum sollte Google eine „andere“ URL im Cache anzeigen?
Vorab sollte man noch erwähnen, dass wir sowohl Canonical als auch Hreflang auf den Kategorieseiten korrekt implementiert haben. D.h. die deutsche URL zeigt per Canonical auf sich selbst und via de-AT Hreflang auf die canonical Variante in AT (vice versa auf der AT URL). Hier haben wir eine sehr hohe Gewissheit, dass das auch über die gesamte Zeit hinweg der Fall war.
Ist das ein Sonderfall oder können wir ein Pattern ableiten?
Eine Quantifizierung des Problems erwies sich als schwierig: Wie findet man raus, für welche URLs Google die URLs eines anderen Landes „cached“? Das Verhalten war definitiv nicht bei allen URLs von www.aboutyou.de der Fall.
Glücklicherweise haben wir auf unseren einzelnen Länder-Domains einige diskriminierende site-wide Elemente, z.B. die Email Adresse des Kundenservice im Footer. Konkret: kundenservice@aboutyou.at sollte nur auf aboutyou.at auftauchen. Für aboutyou.de müsste es kundenservice@aboutyou.de sein.
Dadurch konnten wir mit dem Query https://www.google.de/search?q=site:aboutyou.de%20%22kundenservice@aboutyou.at%22 zumindest feststellen, dass es sich nicht um einen Einzelfall handelte.
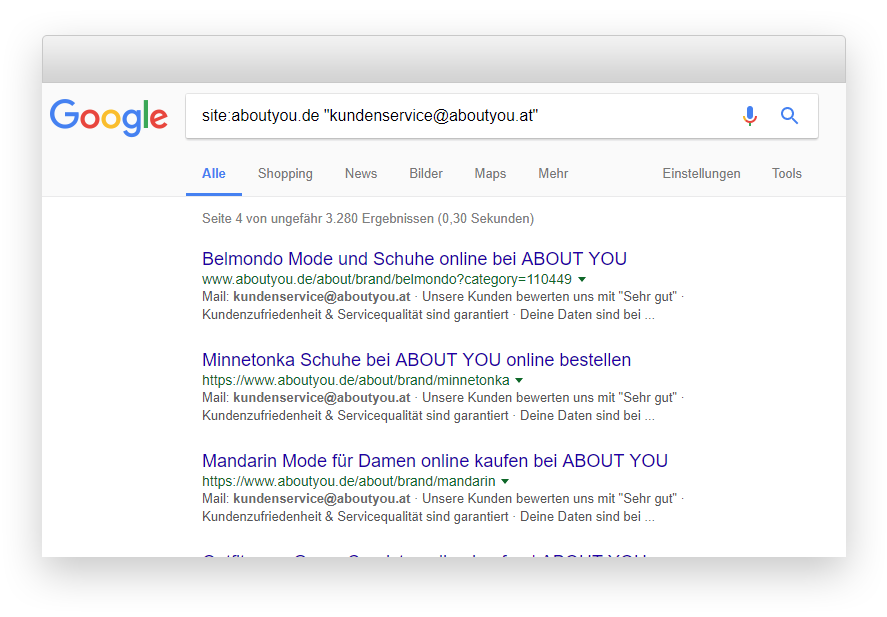
Wie verhalten sich andere Webseiten, die in mehreren Ländern aktiv sind?
Ich muss allerdings zugeben, dass ich solche Suchanfragen nicht häufig durchführe und es könnte auch durchaus legitim sein, dass Google bei einer solchen Anfrage das „site:“ einfach ignoriert. Gerade bei site: Queries kommt es gerne mal zu Nebeneffekten.
Das ist mir damals schon bei Tchibo aufgefallen, weil ich irgendwann mal site:www.tchibo.at gecheckt habe und dafür auch Ergebnisse mit www.tchibo.at URLs bekam – obwohl die Seite schon immer per 301 auf eduscho.at weitergeleitet hat.
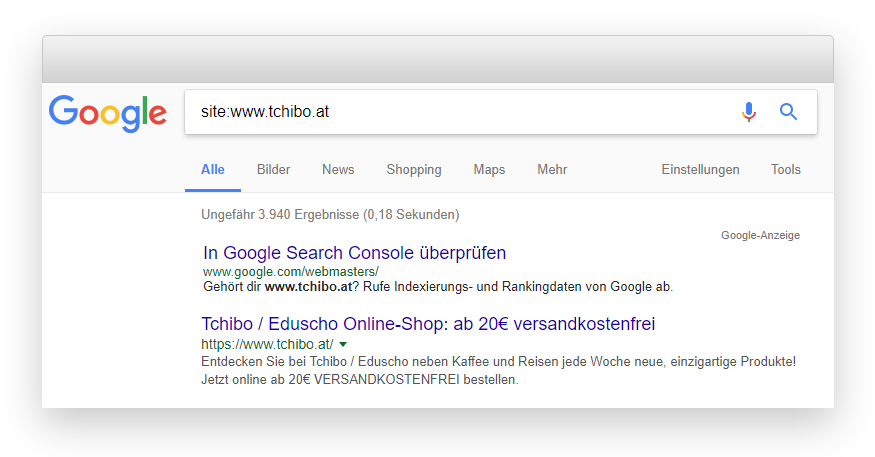
Klar, anderes Setup aber ein Beispiel dafür, dass man bei sowas lieber zweimal hinschauen sollte.
Um also sicher zu gehen, dass wir einem „echten“ Problem auf der Spur sind, musste ein Vergleich her. Auch hier bot sich Tchibo an, weil mir die Implementierung geläufig war und ich wusste, dass Hreflang und Canonical Infos korrekt und seit ausreichend langer Zeit implementiert waren. Als Unterscheidungsmerkmal diente in diesem Fall die Bestellhotline, die auf jeder Seite im Footer verlinkt ist:
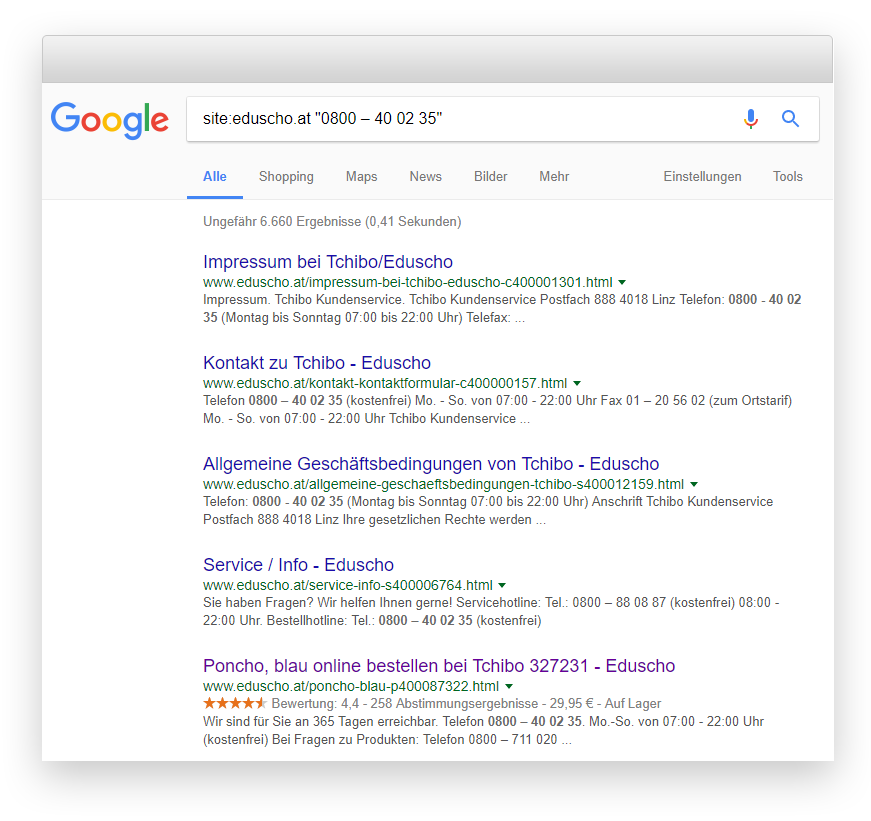
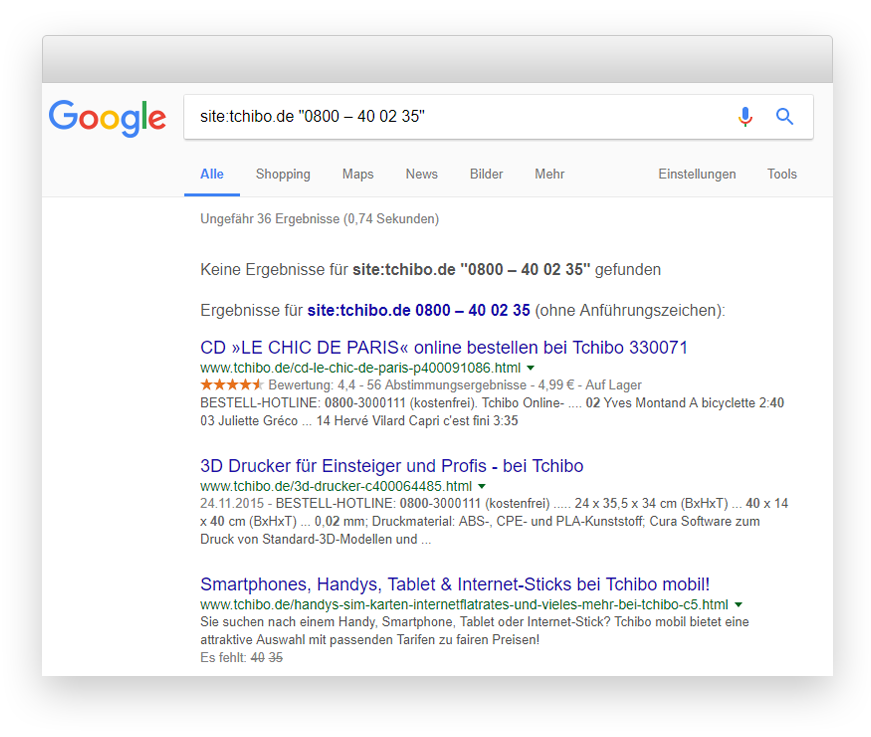
Nope, keine Ergebnisse. Wir haben noch einige andere Domains getestet, aber das Ergebnis war das gleiche: Auch bei einer site: Abfrage spielt Google nicht den Content einer anderen Domain aus, auch wenn diese via Hreflang „verlinkt“ ist. Scheinbar liegt bei uns also wirklich etwas im Argen.
Warum sollte Google eine „andere“ URL im Cache anzeigen?
Die Antwort auf diese Frage scheint eindeutig: Immer dann, wenn eine „andere“ URL für das Ranking relevant ist, wird diese im Cache von Google angezeigt. Das tchibo.at Beispiel macht das deutlich – ein Blick in den Cache zeigt hier erwartungsgemäß „eduscho.at“.

In diesem Falle scheint es jedoch offensichtlich, da es sich um eine 301 Weiterleitung handelt.
Dennoch war unser Zwischenfazit bisher:
Aus irgendeinem Grund verwendet Google unsere österreichische Domain als Basis für das Ranking im deutschen Index. Das dabei trotzdem weiterhin die deutschen URLs angezeigt werden, ließe sich durch die hreflang Angaben erklären, denn genau das tut Hreflang ja: Google „rankt“ die eine Domain, aber spielt in den SERPs die andere aus, weil sie besser auf das Land passt.
Aber weiter in der Diagnose. Welche Möglichkeiten gibt es sonst noch um URLs zu konsolidieren? Eigentlich nur weitere Weiterleitungen (3xx Status Codes), Canonical Tags, Hreflang Tags oder Alternate Mobile Tags. In einigen Sonderfällen möglicherweise auch noch „identischer“ Inhalt (Google dürfte dann „eigenständig“ ermitteln, welche URL als Canonical gewertet wird).
Oder gar extern: Ein expliziter Seitenumzug angestoßen durch die Search Console. Hat da also jemand…?
Analyse der Daten der Search Console
Die entsprechenden Einstellungen werden unter https://www.google.com/webmasters/tools/change-address?hl=de&siteUrl=https://www.aboutyou.de/ vorgenommen, aber dort zeigte sich nichts Auffälliges:
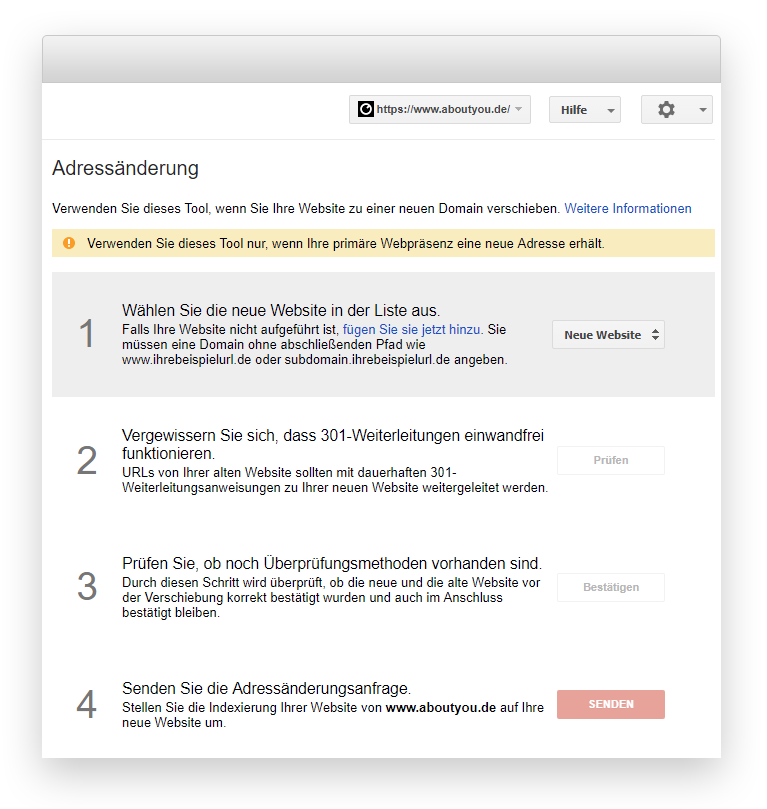
Zum Vergleich: So würde es aussehen, wenn tatsächlich ein Seitenumzug beantragt worden wäre:
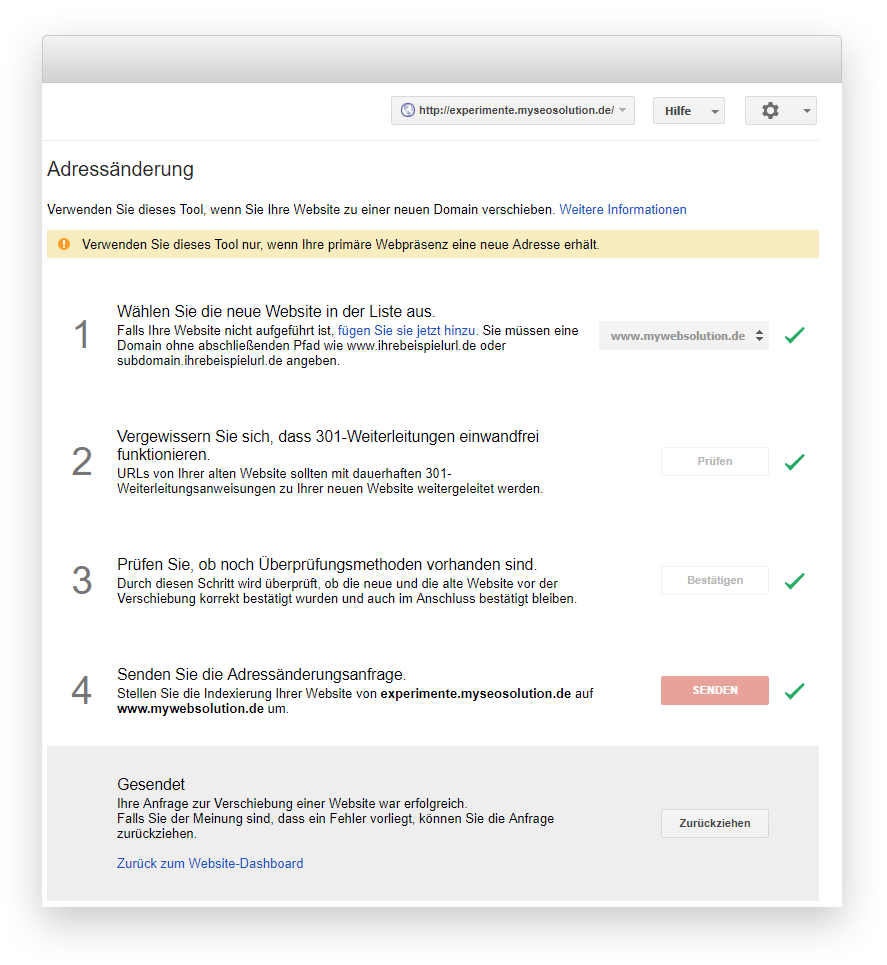
Außerdem muss für Schritt 2 ein 301 Redirect eingerichtet werden – das wäre dann doch aufgefallen ;) Ein Blick in die Suchanalyse zeigte einen leichten Traffic-Anstieg für AT und CH bei in etwa gleichbleibender Performance für DE. Nichts, was direkt negativ auffällig war.
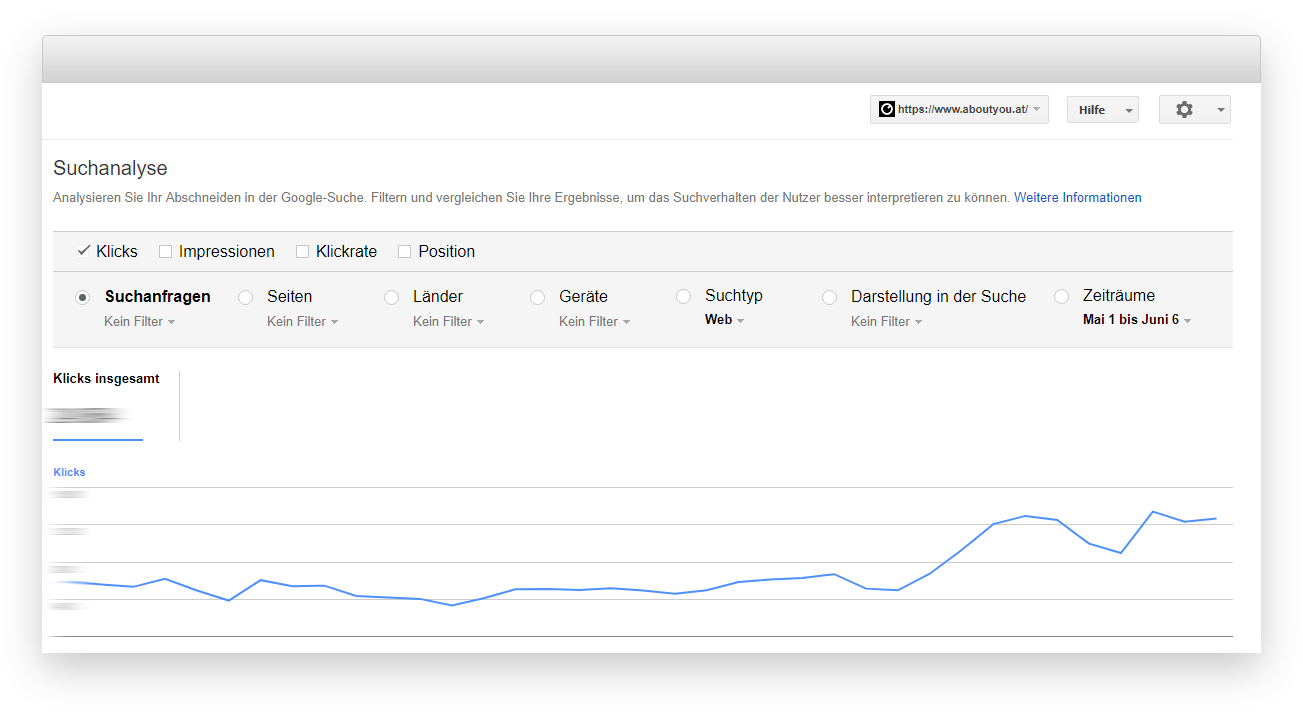
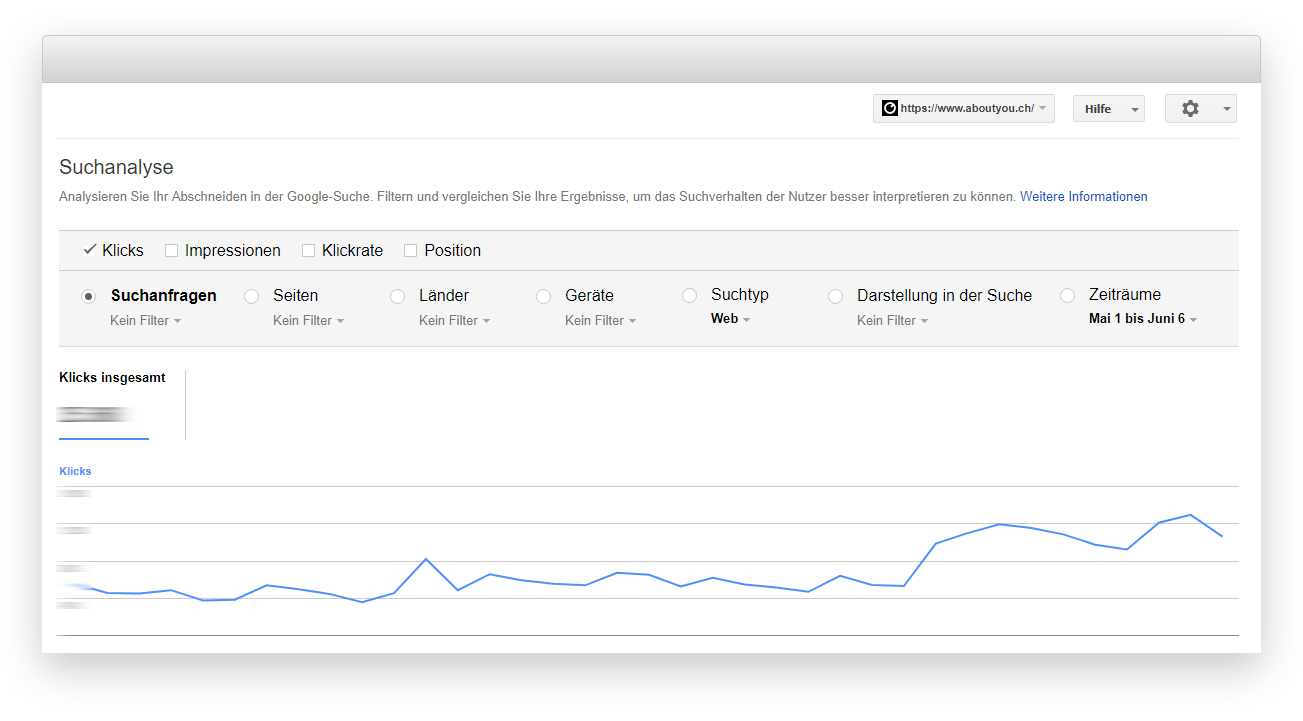
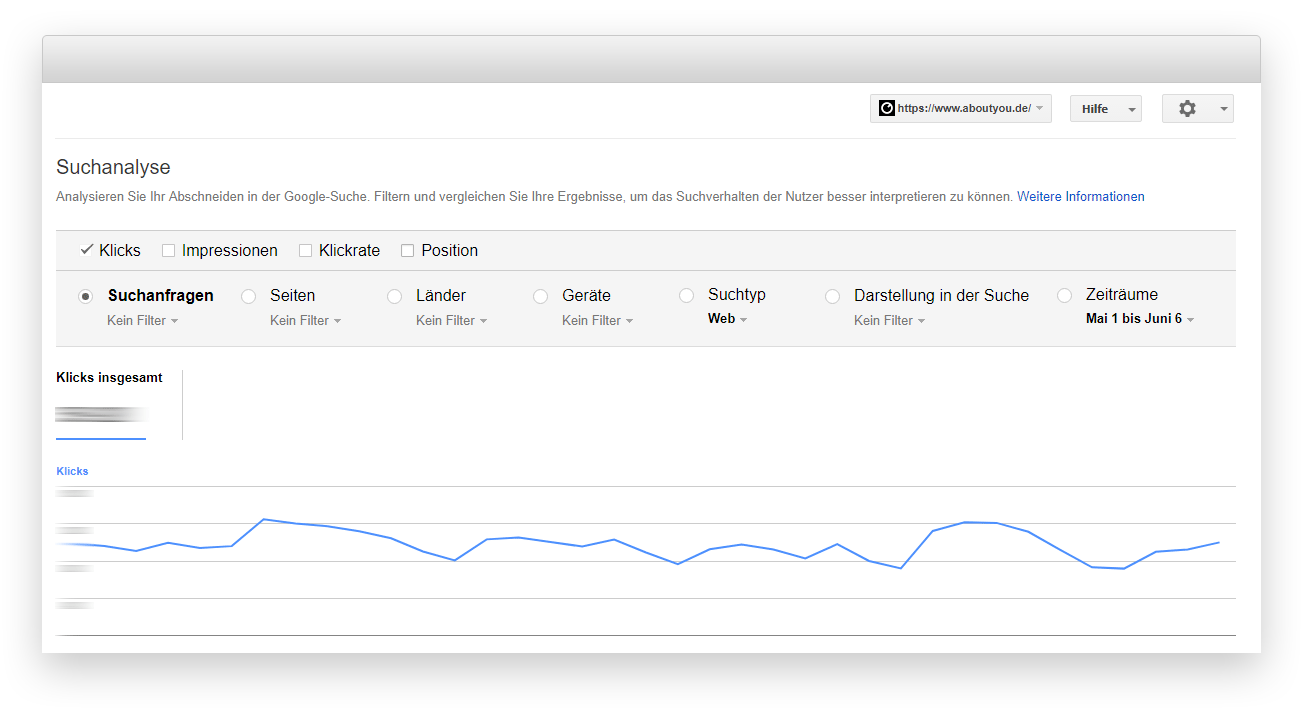
Auffällig war hingegen der Report zur Internationalen Ausrichtung – vor allem für aboutyou.at.
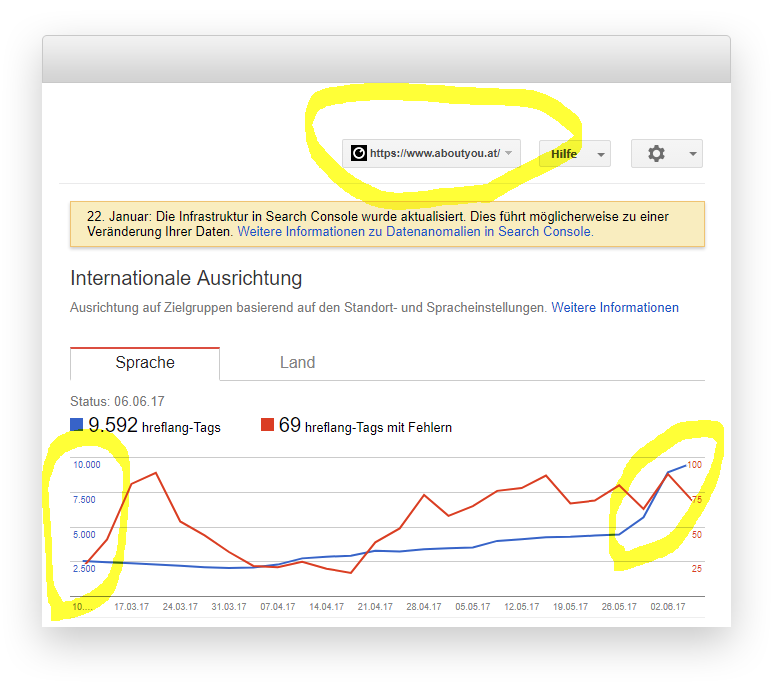
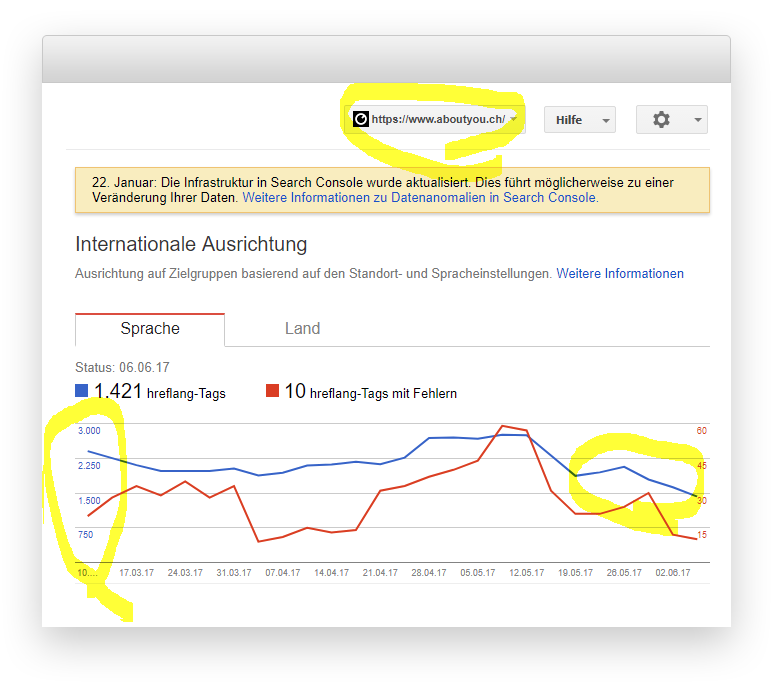
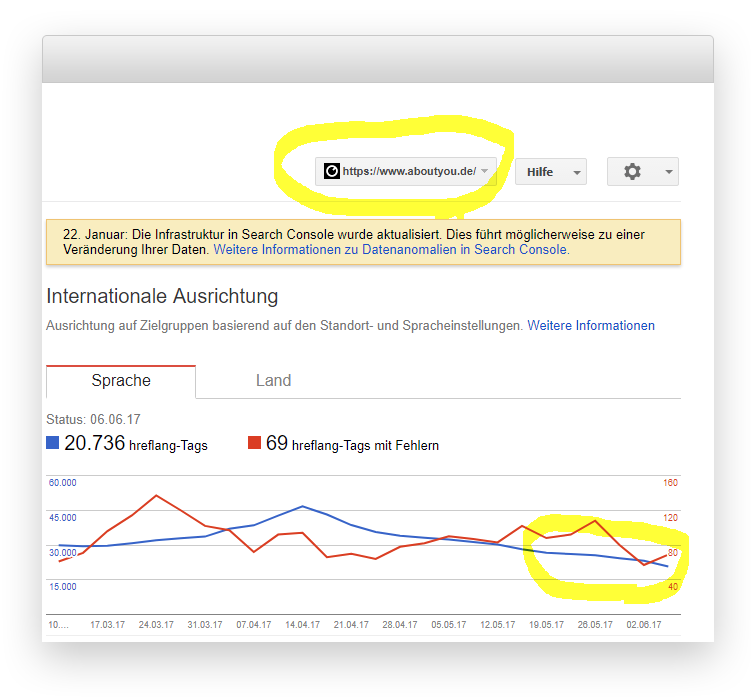
Insgesamt zwar „interessant“ aber nicht wirklich hilfreich in punkto Problemdiagnose. Unterm Strich also eher enttäuschend, was Google hier an Infos zur Verfügung stellt. Dass die Daten um ein paar Tage zurückhängen macht die Sache leider nicht besser (man beachte das „Status: 06.06.2017“ im „Internationale Ausrichtung“ Report)
Also auf zum nächsten Punkt.
Re-Evaluierung von Tickets aus den letzten Deployments im Shop
In der Woche vor dem Sichtbarkeitseinbruch haben wir zwei Features/Bugfixes deployt, die einen direkten Einfluss auf das Crawling-Verhalten von Google haben:
Ticket: „Googlebot for Smartphones currently not recognized“
Seit März 2016 nutzt Google einen anderen User Agent zum Smartphone Crawling. Da wir eine mobile Subdomain einsetzen (https://m.aboutyou.de/) und Smartphone User beim Aufruf der Desktop-Seite dorthin weiterleiten, sollte Google genauso behandelt werden.
Diese Redirects werden bei uns direkt im Varnish durchgeführt (unser http Cache; mehr dazu). Das ist zwar extrem schnell, aber traditionell ziemlich schwer zu testen. Zusätzlich werden dort ebenfalls unsere Geo-Redirects ausgesteuert – könnte es sein, dass dabei etwas schiefgelaufen ist und Google beim Aufruf der deutschen Seite zu einem anderen Land weitergeleitet wird?
Da wir bei unseren Tickets versuchen, die Nachkontrolle so effizient wie möglich zu gestalten, hat sich für solche Checks bash scripting in Kombination mit curl bewährt, weil es genügend Flexibilität bei überschaubarem Aufwand und einfacher Teilbarkeit gewährleistet. Das folgende Script war also bereits als Kommentar hinterlegt:
In anderen Worten: Rufe die Startseiten von unseren Länder Domains mit unterschiedlichen User-Agents auf, folge etwaigen Weiterleitungen und gib die URLs inklusive Status Codes dazu aus.
Der Output war wie erwartet:
Nur der mobile Crawler wird beim Aufruf der Desktopseite auf die mobile Variante weitergeleitet, der normale Googlebot bekommt aber in jedem Fall einen 200 Status Code.
Zwar hätten wir zur vollständigen Sicherheit noch einen Proxy aus den USA nutzen müssen, aber die Redirects schienen wie geplant zu funktionieren. Als normaler Nutzer (ohne Googlebot User-Agent) wäre ich z.B. beim Aufruf von www.aboutyou.at defaultmäßig auf www.aboutyou.de weitergeleitet worden.
Das schien also nicht das Problem zu sein.
Ticket: „Homepage Go-Live“
Auf der „code.talks commerce special 2017“ hat unser CTO Sebastian Betz mehr oder weniger in einem Nebensatz fallen lassen, dass wir unser Shop Frontend gerade auf einen komplett neuen, React-basierten Stack umstellen. Mittelfristig wird der Shop dann zu einer Single Page Application, mit all den Herausforderungen, die das an das SEO stellt.
Da das technologisch ein ziemlich heftiges Brett ist, ziehen wir sukzessive einzelne Bereiche der Seite um und sind mit unserer Startseite gestartet. Daran sind bei uns (jeweils für DE, AT und CH) konkret folgende URLs geknüpft:
- https://www.aboutyou.de/
- https://www.aboutyou.de/frauen
- https://www.aboutyou.de/maenner
Nun sollte man an dieser Stelle noch erwähnen, dass die Seiten serverseitig via NodeJS pre-rendered werden und hier einfach mal fundamental andere Paradigmen gelten als bei PHP basierten Applikationen (Single Request Lifecycle vs. non-blocking Event Loop). Hier gibt es also so richtig viel Potenzial für nicht offensichtliche Probleme.
Nichtsdestotrotz sind die URLs im neuen Stack durch die übliche QA gelaufen (inklusive Canonical und Hreflang Check) und waren in allen Kriterien fehlerfrei. Naja, meistens…
Die Sache mit der Konsistenz
Wie sich später herausstellte hatten wir bei dem initialen Deployment mit sog. Race Conditions zu kämpfen. Race Conditions sind in der Informatik fehlerhafte Zustände, die durch parallele Prozesse zu Stande kommen. Oder anders: Wenn zwei Personen gleichzeitig am gleichen Dokument arbeiten, dann kann es schonmal passieren, dass die erste Person etwas speichert, was die zweite Person überschreibt. Und Person eins ist dann ziemlich perplex, weil ihre Arbeit futsch ist.
Das Blöde an dieser Art von Problemen ist, dass sie nur unter bestimmten Umständen auftreten und sich dadurch extrem schwer reproduzieren und beheben lassen.
Dem Problem auf der Spur
Glücklicherweise haben wir bereits vor einiger Zeit intern begonnen, ein umfassendes, automatisiertes Testing Tool zu entwickeln. Dabei werden fest definierte URLs regelmäßig (damals 24, aktuell ca. 150 Mal pro Tag) gecrawlt, archiviert und auf diverse Faktoren geprüft. Darunter unter anderem Status Codes, Canonical Tags und Hreflang Infos.
Kurz nach dem Deployment des obigen Tickets gab es sporadische Alerts, dass einige Checks fehlschlugen – allerdings auf absurde Art und Weise. So wurde zum Beispiel berichtet, dass der Canonical Tag von https://www.aboutyou.de/ auf https://www.aboutyou.at/ zeigen sollte.
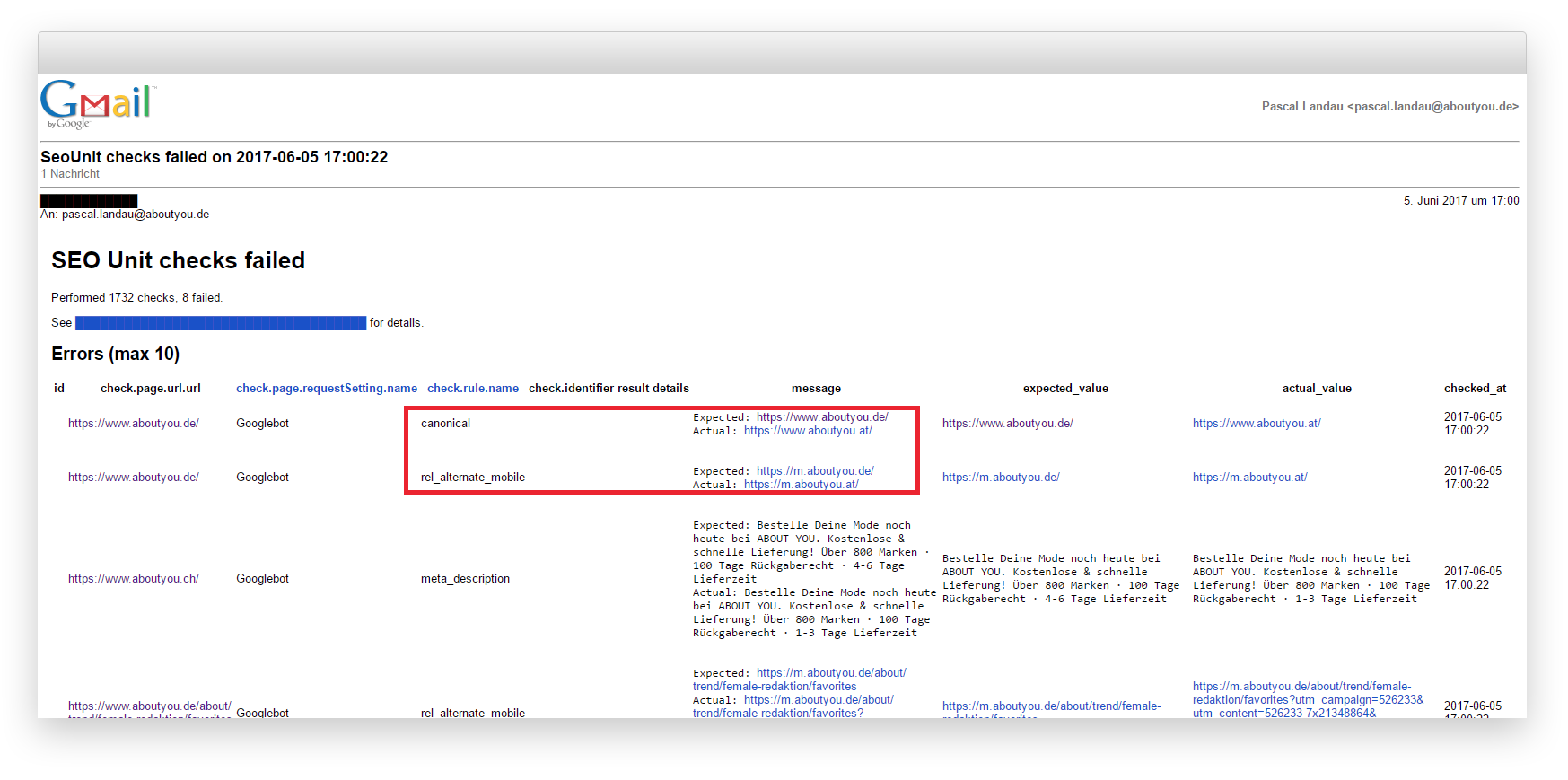
Da zu jedem Check die komplette Response (inklusive Header und Body) gespeichert wird, konnten wir aber sicher sagen, dass der Fehler zum Zeitpunkt des Crawlens tatsächlich vorhanden war. Diese spezifischen Fehler traten wohlgemerkt nur auf den drei URLs (pro Land) auf, die vom neuen Stack betroffen waren.
Der oben beschriebene Fall ist zwar nicht zwingend das, was auch Google beim Crawlen gesehen hat. Es zeigt aber, dass die Ausspielung der Canonicals inkonsistent war, denn diese Fehler traten zwar mehrfach aber eben nur sporadisch auf.
Dieses Problem war uns beim Auftritt des Sichtbarkeitseinbruchs bereits bekannt. Allerdings war die Prio des Bug Tickets als „niedrig“ eingestuft, denn eigentlich war die „Angriffsfläche“ massiv eingeschränkt – schließlich handelte es sich um lediglich drei URLs pro Domain und die sollten wohl keinesfalls für einen 30%igen Verlust der Sichtbarkeit verantwortlich sein (zumal sich das ja auch in Sistrix entsprechend gezeigt hätte).
Dennoch war es die „heißeste“ Spur, die wir hatten und auf Grund der zuvor ermittelten Anomalien (österreichischer Cache bei deutscher URL) sind wir uns relativ sicher, dass es sich ungefähr so zugetragen haben muss:
Unsere deutsche Startseite war auf Grund der Race Conditions sporadisch der Meinung, dass sie eigentlich die österreichische Startseite ist. Und das hat sie auch kundgetan – zum Beispiel über den Canonical Tag. Google hat aber vermutlich keine Entscheidung auf URL Basis getroffen, sondern einfach angenommen, dass wir global alles von www.aboutyou.de auf www.aboutyou.at ziehen wollen statt „nur“ die Startseite und daraufhin angefangen weitere URLs „um zu ranken“.
Da /frauen und /maenner ebenfalls betroffen waren, wurden die Unterseiten zu diesen Verzeichnissen entsprechend schneller neu bewertet und schlagen sich heftiger in der Sichtbarkeit nieder (Achtung, dieser Part ist nun wirklich ziemlich spekulativ).
„Lösung“ und Status Quo
Nachdem die Wurzel des Problems identifiziert schien, haben wir möglichst schnell einen Hotfix am Freitag (09.06.2017) deployt, der endlich wieder ein „sauberes“ und vor allem konsistentes Canonical Setup garantierte.
Zusätzlich haben wir die Startseiten aller Länder via Search Console submitted um Google möglichst schnell unseren Fix mitzuteilen. Und dann… begann das Warten. Letztendlich hatten wir keinerlei Garantie, dass das a) das Ursprungsproblem war und wir b) mit dem Fix alles Notwendige getan hatten. Da der Sichtbarkeitsverlust in Etappen von Statten ging war davon auszugehen, dass eine etwaige Recovery ebenfalls nicht von heute auf morgen zu sehen wäre.
Am Freitagabend konnte ich zumindest für Keywords wie „Damenmode online“ (/frauen) und „Herrenmode online“ (/maenner) wieder Rankings feststellen. Es sah also gut aus. Um ganz sicher zu gehen versuchte ich zusätzlich eine „offizielle“ Aussage von Google zu bekommen:
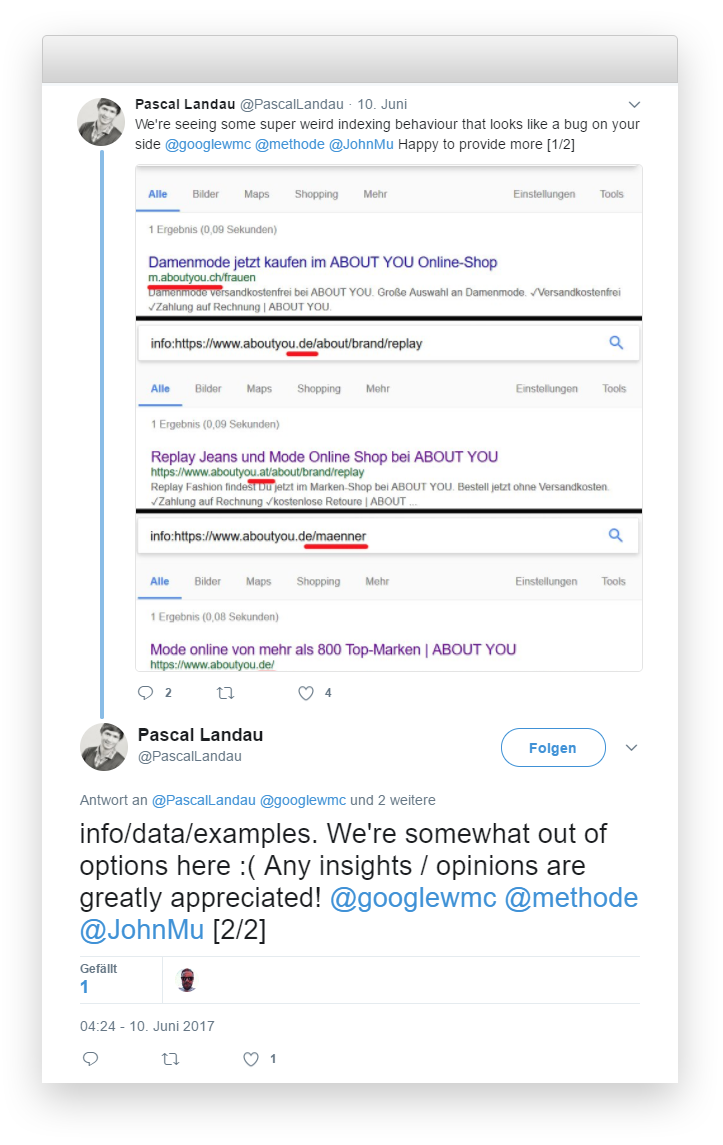
Was zwar nicht funktionierte, aber immerhin andere SEOs auf das Problem aufmerksam machte. An dieser Stelle nochmal danke an @BastianGrimm, der einige Details eines ähnlichen Falls mit mir teilte. Hier scheint also tatsächlich Google nicht ganz unschuldig zu sein. Eine entsprechende Bestätigung wäre also immer noch höchst willkommen ;) Eine inoffizielle Bestätigung, dass sich die noch betroffenen Unterseiten beim nächsten Crawlen wieder erholen haben wir inzwischen erhalten.
Zum Glück bestätigte uns auch die Sichtbarkeitsentwicklung:
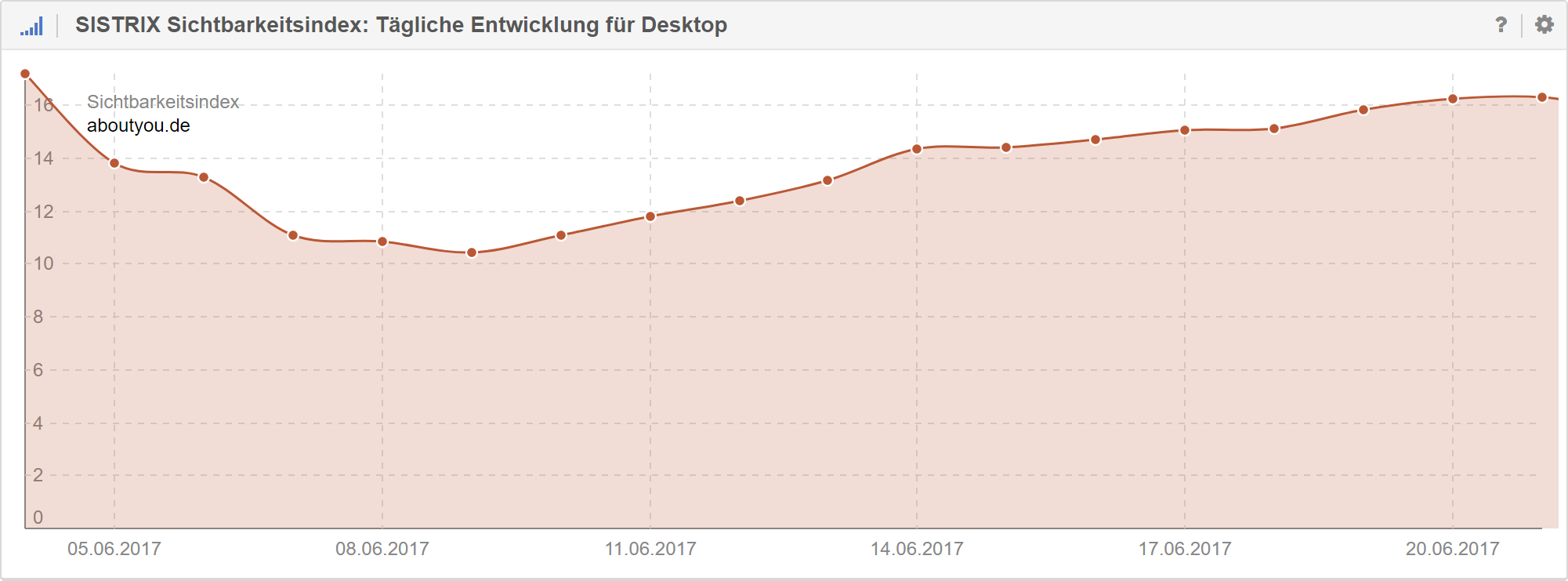
Als ungewollten, aber durchaus positiven Nebeneffekt konnten wir übrigens zusätzlich massive Verbesserungen in AT und CH feststellen. Wird vermutlich nicht auf dem Niveau bleiben, aber schaut nicht schlecht aus.
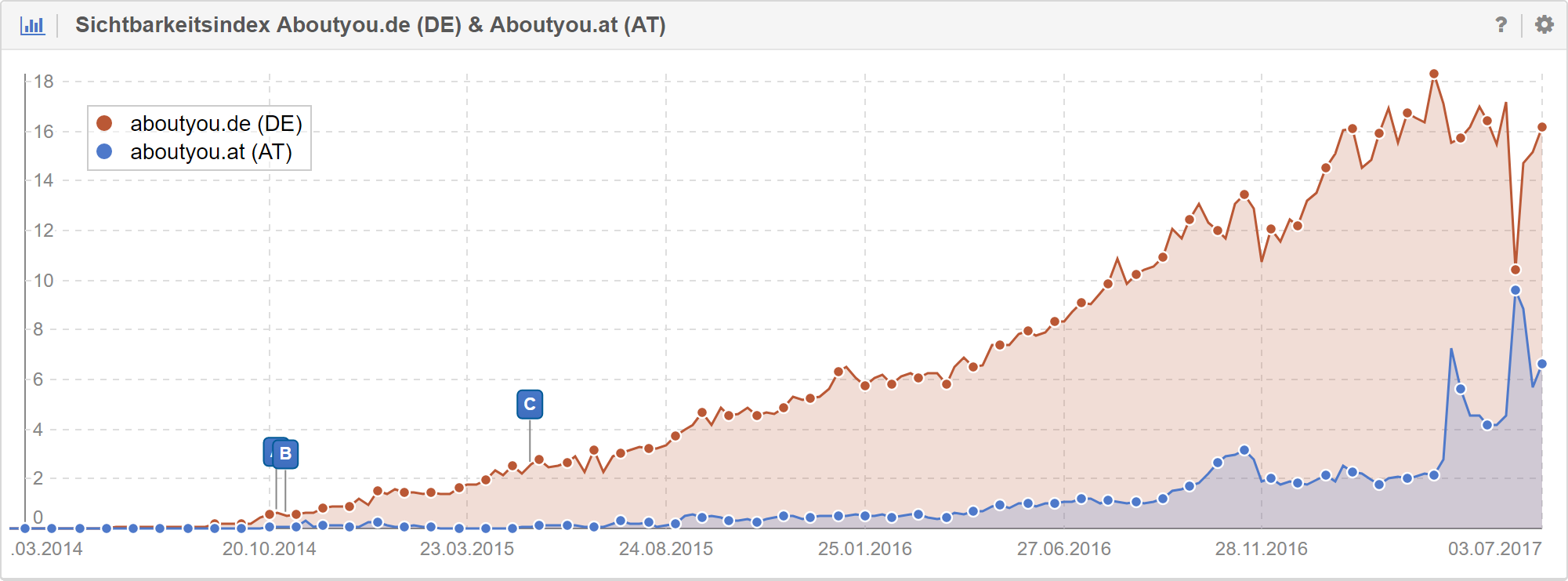
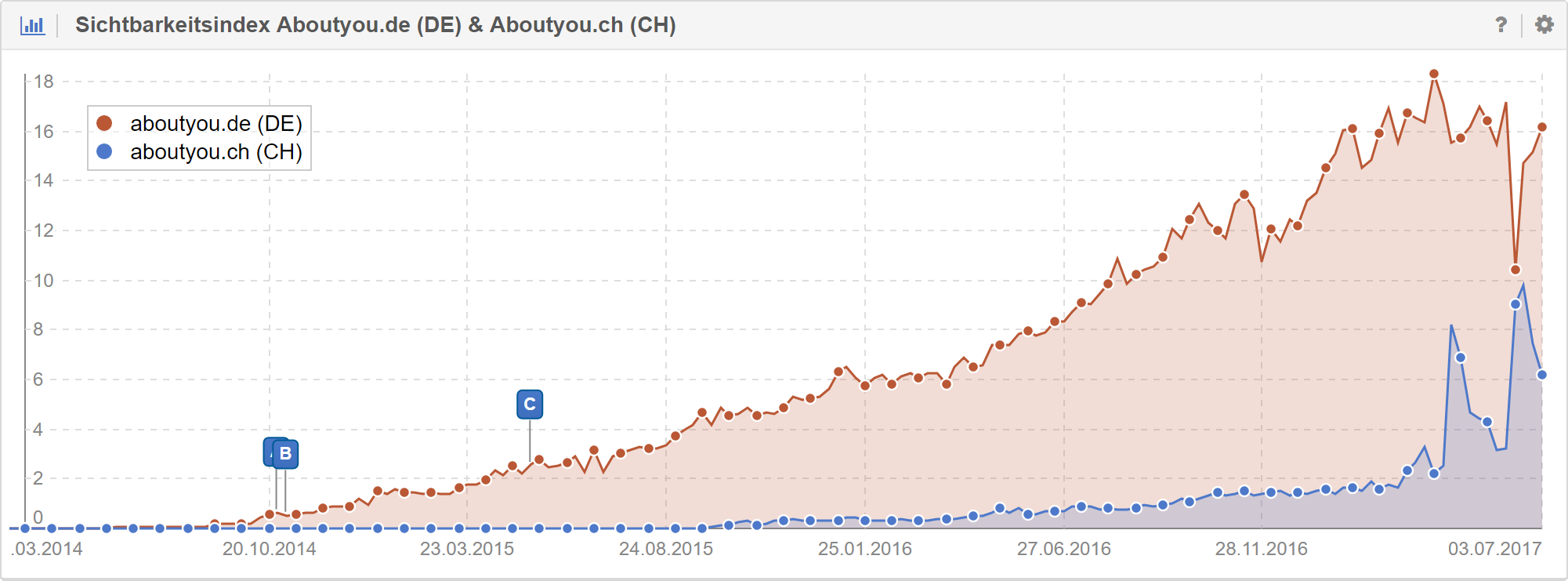
Fazit
Unter Strich bleibt die Frage: Was ist „tatsächlich“ passiert und wie können wir es in Zukunft vermeiden?
Als tl;dr würde ich es wie folgt formulieren:
Durch einen Fehler bei der Umstellung auf einen neuen Technologie-Stack haben wir temporäre Inkonsistenzen bei der Ausspielung unserer Canonical Informationen für die Startseite an Google übermittelt. Das hat ausgereicht, damit Google unsere gesamte deutsche Domain mit der österreichischen konsolidiert und nur letztere zur Ermittlung des Rankings verwendet (auch im deutschen Index).
Durch die Behebung des Bugs auf unserer Seite sowie das zeitnahe Übermitteln über die Search Console erholen sich die dadurch verlorenen Rankings kontinuierlich wieder.
Da wir keine definitive Aussage von Google bekommen werden und ich nicht den Anspruch erhebe, sämtliche Faktoren eingeschlossen zu haben, habe ich die Meinung/Erfahrung einiger weiterer Kollegen* eingeholt. Daraus ergaben sich ergänzend weitere mögliche Faktoren:
- In mindestens zwei weiteren Fällen gab es ein ähnliches Problem bei der Umstellung von http auf https (Google „rankt“ auf einmal die https Variante statt der http Variante). In einem Fall waren keine/nur teilweise Canonicals gesetzt und im anderen wurden relative (statt absolute) verwendet. Grundproblem aber auch hier: „Plötzlich“ site-wide Anpassung des Rankings.
- Identischer Content scheint ein Problem zu sein, selbst wenn Canonical und Hreflang korrekt implementiert sind. Das kann bei uns auch ein Faktor gewesen sein, weil wir zum Teil die gleichen Inhalte verwenden. Vermutung geht hier dahin, dass es einen „Threshold“ für die Kombination verschiedener Signale gibt (gleicher Content, Hreflang, Canonical, …) und bei Google dann irgendwann ein Schalter kippt.
- In einem weiteren Fall wurde einer der stärksten Backlinks (site-wide, starke Authority) von .com auf .at geändert. Also die linkgebende Seite hat sich geändert, nicht das Linkziel. Kurz darauf sind die Rankings in DE eingebrochen und in AT gestiegen.
*Dank geht an:
Wie können wir so etwas in Zukunft verhindern?
Den wichtigsten Schritt haben wir bereits mit Einführung unseres Monitoring Tools gemacht. In der aktuellen Entwicklungsphase von About You (neue Technologien, viele Deployments, starke Skalierung) können wir uns nicht mehr auf „manuelle“ Prüfungen verlassen. Es gibt inzwischen einfach zu viele Faktoren, die Fehler nur unter bestimmen Situationen entstehen lassen (Race Conditions, Caching Probleme, mehrere Application Server mit unterschiedlichen Code Ständen).
Tests müssen deshalb regelmäßig und automatisch laufen, auf allen Systemen (von Integration bis Production) um etwaige Bugs frühzeitig erkennen und beheben zu können. Diese Erkenntnis konnte ich 1-zu-1 aus der Software-Entwicklung übertragen, wo ich mit dieser Philosophie sehr gute Erfahrungen gemacht habe.
Zusätzlich werden wir sämtliche Bugs die in Richtung inkorrekte Canonicals gehen radikal hoch-priorisieren. Dieses Problem hat gezeigt, dass selbst vermeintlich klar abgrenzbare Probleme („es waren nur drei URLs betroffen“) unerwartete Ausmaße annehmen können. Leider sind wir hier immer noch in einer Abhängigkeit von Google die uns im Zweifel keinen Fehler erlaubt.
Wir haben während der Analyse noch ein paar weitere Erkenntnisse gewinnen können, die für diesen Artikel nicht unbedingt relevant sind, aber Webmastern mit ähnlichen Problemen eventuell weiterhelfen können (z.B. Delays beim Refresh des Google Caches). Also gerne kommentieren oder direkt an mich wenden (Xing, LinkedIn, Twitter).
Shameless Plug zum Schluss: Gleiches gilt übrigens, wenn ihr das nächste Mal hautnah dabei sein möchtet. Oder in anderen Worten: Analytisch denkende, zahlengetriebene und vor allem lernfreudige, hochmotivierte SEOs sind immer gerne gesehen.